Abstract
This research is a collaboration involving a university team, a partnering corporation, and a hemodialysis clinic, which is a cross-disciplinary research initiative in the field of Artificial Intelligence of Things (AIoT) within the medical informatics domain. The research has two objectives: (1) The development of an Internet of Things (IoT)-based Information System customized for the hemodialysis machines at the clinic, including transmission bridges, clinical personnel dedicated web/app, and a backend server. The system has been deployed at the clinic and is now officially operational; (2) The research also utilized de-identified, anonymous data (collected by the officially operational system) to train, evaluate, and compare Deep Learning-based Intradialytic Blood Pressure (BP)/Pulse Rate (PR) Predictive Models, with subsequent suggestions provided. Both objectives were executed under the supervision of the Institutional Review Board (IRB) at Mackay Memorial Hospital in Taiwan. The system completed for objective one has introduced three significant services to the clinic, including automated hemodialysis data collection, digitized data storage, and an information-rich human-machine interface as well as graphical data displays, which replaces traditional paper-based clinical administrative operations, thereby enhancing healthcare efficiency. The graphical data presented through web and app interfaces aids in real-time, intuitive comprehension of the patients’ conditions during hemodialysis. Moreover, the data stored in the backend database is available for physicians to conduct relevant analyses, unearth insights into medical practices, and provide precise medical care for individual patients. The training and evaluation of the predictive models for objective two, along with related comparisons, analyses, and recommendations, suggest that in situations with limited computational resources and data, an Artificial Neural Network (ANN) model with six hidden layers, SELU activation function, and a focus on artery-related features can be employed for hourly intradialytic BP/PR prediction tasks. It is believed that this contributes to the collaborating clinic and relevant research communities.
1. Introduction
The progression of chronic kidney disease (CKD) is categorized into five stages [1], with end-stage CKD necessitating renal replacement therapy. Hemodialysis [2] is one of the primary renal replacement therapies, substituting the kidneys’ metabolic and fluid removal functions. Hemodialysis operates on the principle of diffusion mass transfer, utilizing membrane separation [3] to transfer metabolic waste from the blood to the dialysate. Additionally, hemodialysis employs ultrafiltration to remove excess fluid. One of the most common complications during dialysis is intradialytic hypotension (IDH) [4], which can be life-threatening. Implementing an information system to enhance monitoring during the dialysis process could be a feasible and beneficial approach for early warning of such complications.
However, despite significant advancements in medical informatics in Taiwan over the past three decades [5], interdisciplinary collaborations in hemodialysis remain relatively scarce. This is due to the challenges in interdisciplinary communication and the relatively recent emergence of technologies such as Internet of Things (IoT) and artificial intelligence (AI), especially deep learning, within the last ten to twenty years. In addition, many clinical hemodialysis machines in dialysis clinics, especially those purchased in earlier years, are not integrated with comprehensive backend clinical information systems and typically lack user-friendly web interfaces or mobile applications (mobile app or app). Moreover, due to Taiwan’s tiered healthcare system, a notable disparity in resources exists between hospitals and clinics. Hospitals, with abundant resources, can quickly integrate information and communication technology (ICT) or acquire highly digitized new medical devices for service upgrades. In contrast, clinics often face cost constraints that hinder their ability to upgrade medical equipment regularly.
Considering these challenges, this research was initiated with collaborating partners including a hemodialysis clinic (Yuanlin Clinic in Taipei, Taiwan) and an information technology (IT) company in Taiwan. Government funding was secured to develop a customized, integrated IoT-based data collection and clinical information system specifically designed for the hemodialysis machines at the collaborating clinic. This system aims to enhance the overall efficiency of hemodialysis services provided by the clinic. Additionally, using the de-identified hemodialysis data collected by this system, this study trained, evaluated, and compared AI-based deep learning models for predicting blood pressure (BP) and pulse rate (PR) during dialysis. The study also provides relevant recommendations, which are expected to contribute to related research communities.
To be specific, the proposed system aims to facilitate the informatization and digitization of the clinic’s processes by converting traditional paper-based medical records into digital data storage and display. This eliminates the need for extensive paper records and the associated storage space concerns. Consequently, it enhances the clinic’s internal efficiency by allowing existing nursing staff to focus more on patient care rather than being burdened by time-consuming tasks such as manual record-keeping, filing, and searching through paper documents. This results in improved clinical and administrative efficiency within the clinic. Moreover, digitized records will aid in the efficient retrieval, review, and diagnosis of patient data, uncovering critical medical insights and enabling precise clinical services for individual patients. In summary, the proposed system supports automated collection of clinical hemodialysis data, real-time and historical data access and display, and clinical order recording with the aid of IoT end devices, web, app, and backend server. Additionally, it allows for the export of de-identified clinical hemodialysis data for subsequent analysis and predictive model training and evaluation, all of which were conducted as part of this study.
In terms of system architecture and functionality, this study utilizes various IoT and ICT techniques to develop the proposed system, which consists of four main components: IoT end devices, a backend web server, an app, and a frontend web interface. The IoT end devices, referred to as transmission bridges, are responsible for collecting data from the hemodialysis machines, converting the data format, and transmitting it to the backend web server for storage. The backend web server, in addition to housing a database for data storage, also includes a website and a web API, allowing the transmission bridges, web interface, and app to perform read and/or write operations on the database. Notably, the user interface (UI) design for the web interface and app was collaboratively developed through multiple meetings between the university team and clinic staff. The interface presents data in a user-friendly, dashboard-style format with graphical representations, which significantly aids clinic staff in reviewing and interpreting patient data. Moreover, the functionality for physicians to input clinical orders directly via the web interface and app streamlines the process beyond the traditional two-step method of handwritten orders and subsequent data entry by nursing staff, enhancing administrative efficiency and reducing related human errors.
This study has successfully completed the system development, verified its feasibility, and deployed it for clinical use at the collaborating clinic. Also, by the de-identified, anonymous data exported from the proposed system, this study has trained, evaluated, and compared two different deep learning predictive models with various hyperparameters and parameters, and proposed relevant suggestions for related research communities. Note that the research has been progressively disseminated. During the project execution phase, preliminary versions of the study were presented at the Third Minghsin University of Science and Technology – Engineering, Technology, and Application Conference in 2023 [6] and at the Wireless, Ad-hoc, and Sensor Networks Conference in 2024 [7], respectively. This paper further consolidates and presents the comprehensive research results, including a detailed discussion on the training, evaluation, comparison, and suggestion of deep learning predictive models for intradialytic BP and PR, as well as a review of the proposed system.
As a final remark, it is important to note that this study did not involve human subjects or the development of medical instruments. The transmission bridges of the proposed system merely retrieve data indirectly from the existing hemodialysis machines at the collaborating clinic via the built-in output ports (Ethernet ports), convert the data format, and then transmit the data via the clinic’s internal wireless network to the clinic’s internal backend server for storage. All other information and data are entered exclusively by the clinic’s medical staff through a dedicated app or web interface. Data analysis and predictive model training and evaluation were conducted solely based on de-identified, anonymous data exported and provided by the collaborating clinic, which means that this study does not identify any specific patients. Also, this study has been rigorously reviewed and completed under the supervision of the Institutional Review Board (IRB) at Mackay Memorial Hospital in Taiwan (IRB no. 21MMHIS375e), with adherence to the agreed data retention period stipulated by the IRB agreement. Once this period expires, all data will be destroyed.
The remaining sections of this paper are organized as follows: Section 2 reviews the literature, Section 3 revisits the design and implementation of the proposed system, Section 4 details the training, evaluation, comparison, and recommendation for the predictive models, and Section 5 provides the conclusions.
2. Literature Review
This section primarily explores the status of data analysis and AI techniques, including machine learning and deep learning, in the field of renal replacement therapy. In recent years, big data analysis and AI have become highly influential in clinical and medical research, with academia and the medical community both domestically and internationally integrating these technologies into various aspects of renal replacement therapy. Numerous studies have been conducted in this area; the following are a few examples: In 2019, researcher Cai [8] published a master's thesis using decision trees to predict subsequent BP of patients based on key parameters such as the number of IDH episodes during the previous dialysis session, current systolic BP, target sodium concentration, dialysis machine number, and set temperature. In 2021, Taipei Veterans General Hospital in Taiwan collaborated with a software company [9] to develop an AI-driven real-time hemodialysis prediction system that can report the risk of heart failure in dialysis patients with an accuracy of up to 90% and evaluate the ideal dry weight of patients, reducing the error by 80%, thereby significantly decreasing morbidity and mortality rates. In 2020, researchers Wang and Song [10] integrated bidirectional long short-term memory (BLSTM) [11] and attention mechanisms [12] to introduce a BLSTM-Attention deep learning model to assist physicians in dialysis treatment based on 32 patient features (including age, pre-dialysis BP, sodium concentration, etc.). In 2019, researchers Barbieri et al. [13] published a multi-layer feedforward neural network model that can predict post-dialysis Kt/V, minimum systolic BP, heart rate, weight, etc. Also in 2019, researchers Wang et al. [14] presented a convolutional neural network (CNN) model to predict the one-year prognosis of patients based on intradialytic BP data from 36 consecutive dialysis sessions. In the same year, researchers Bi et al. [15] published a time-series-based regression model to estimate weight changes of patients, aiding physicians in monitoring dry weight settings. Xiong et al. [16] introduced a model combining LVW embedded model feature selection and ensemble learning to assist in decision-making for dialysis timing. Finally, according to a literature review by researchers Burlacu et al. [17], it is evident that using data analysis and AI techniques in the three major renal replacement therapies (hemodialysis, peritoneal dialysis, and kidney transplantation) has become a trend. However, the perspectives and attitudes towards this trend differ significantly between the IT sector and the medical community. The IT sector tends to see the potential of these technologies and anticipates improved clinical efficiency through their integration. On the other hand, the medical community, which relies heavily on evidence-based medicine (EBM) [18], is more concerned with the feasibility, safety, and practical benefits of these technologies, thus maintaining a cautious stance towards new IT initiatives, especially the introduction of black-box deep learning models. Indeed, closer communication and collaboration between the IT and medical communities are essential to ensure the successful application of new technologies and the safety of dialysis patients. From the IT perspective, this study agrees that research and development teams should delve deeper into understanding the challenges faced by the medical community and pragmatically adjust the application of technologies based on clinical situations to ensure a positive impact on medical practice. Conversely, if the medical community adopts a more open mindset towards new technologies, they may gradually appreciate the supportive power of these innovations in clinical applications.
After examining the relevant research trends, this study then reflects on the current situation in Taiwan. Truly, some related studies have been conducted by cross-disciplinary teams, including those at Taipei Veterans General Hospital. However, it is regrettable that due to Taiwan’s tiered healthcare system, clinics with relatively scarce resources still find it difficult to have sufficient funding and capacity to integrate ICT with their currently existing old medical equipment or purchase highly digitized new medical devices for service upgrades. This becomes the entry point and focus of this research. With the support of government funding and the deliberation of cross-disciplinary partners, this research gained the invitation of the collaborating clinic to implement the proposed system on-site, allowing the proposed system to leverage ICT to improve the medical and administrative efficiency of the clinic, despite the relative scarcity of resources in such settings. Moreover, the collected de-identified hemodialysis data allows for subsequent analysis as well as predictive model training and evaluation, which may further support the physicians in enhancing patient care and improving clinical outcomes.
3. Detailed Overview of the Proposed System
3.1. System Overview
This study integrated various IoT and ICT ingredients, including microcontrollers, Ethernet, Wi-Fi, Web API, app, website frontend and backend, and database, to design and develop a specialized IoT information system for the collaborating clinic. This system consists of four main components: (1) transmission bridges (which capture hemodialysis data from the clinic’s existing hemodialysis machines via the Ethernet port, converts the data format, and transmits it to the backend server via Wi-Fi), (2) a dedicated app for medical personnel, (3) a web-based frontend interface for medical personnel, and (4) a backend server (including a database, Web API, and website backend). The system provides two main functions: (1) capturing, format converting, forwarding, and storing hemodialysis data, and (2) enabling medical personnel to look up and view patients’ data/charts and input other relevant data and information. The overall system architecture is illustrated in Figure 1. It should be noted that the hemodialysis machines were not developed as part of this research but are existing medical equipment at the clinic. In Figure 1, these machines are included only to serve as the foundational equipment that the proposed system was designed to support and enhance. The following sections will detail the design and implementation of the transmission bridge, the dedicated app and web interface for medical personnel, and the backend server.

3.2. Design and Implementation: Transmission Bridge
The transmission bridge developed in this research was constructed from IoT hardware and its internal firmware. From a hardware and low-layer communication perspective, since the clinical hemodialysis machines at the collaborating clinic are already equipped with Ethernet ports that can be connected via twisted pair cables, and the clinic is also equipped with Wi-Fi access points, the research selected the WT32-ETH01 microcontroller module, which supports both Ethernet and Wi-Fi communication, for implementing the transmission bridge. Each transmission bridge interfaces with a hemodialysis machine via a twisted pair cable connecting their Ethernet ports, allowing it to access the hemodialysis data. The transmission bridge then converts the data format and sends the converted, acquired data to the backend server through Wi-Fi. In terms of firmware and upper-layer communication, the core tasks of the firmware within the transmission bridge are twofold: (1) converting the hemodialysis machine data from its original format to JSON format; (2) calling the backend Web API developed in this research to write the JSON-formatted data into the backend server’s database. The completed transmission bridge is demonstrated in Figure 2.

3.3. Design and Implementation: Dedicated App for Medical Personnel
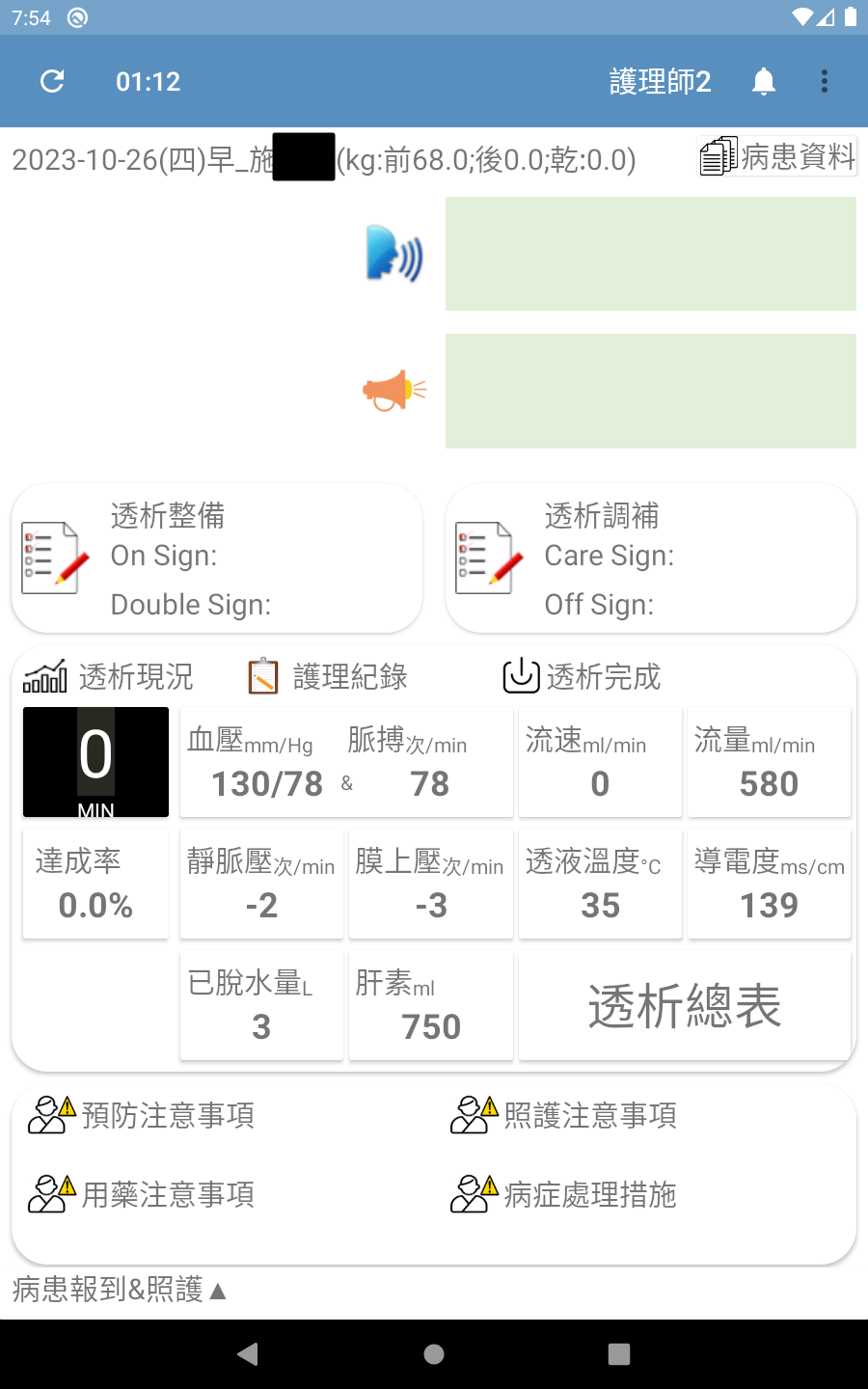
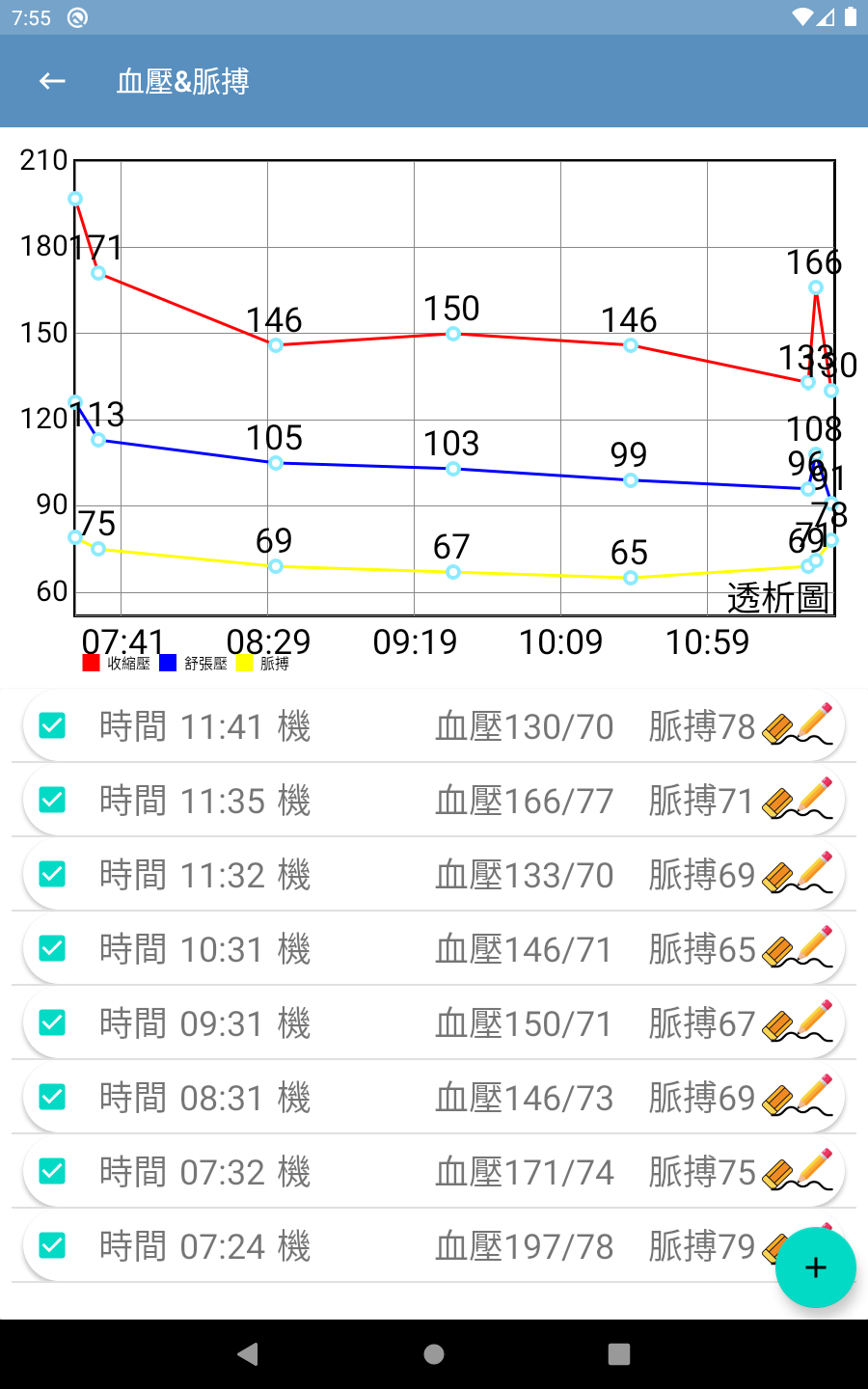
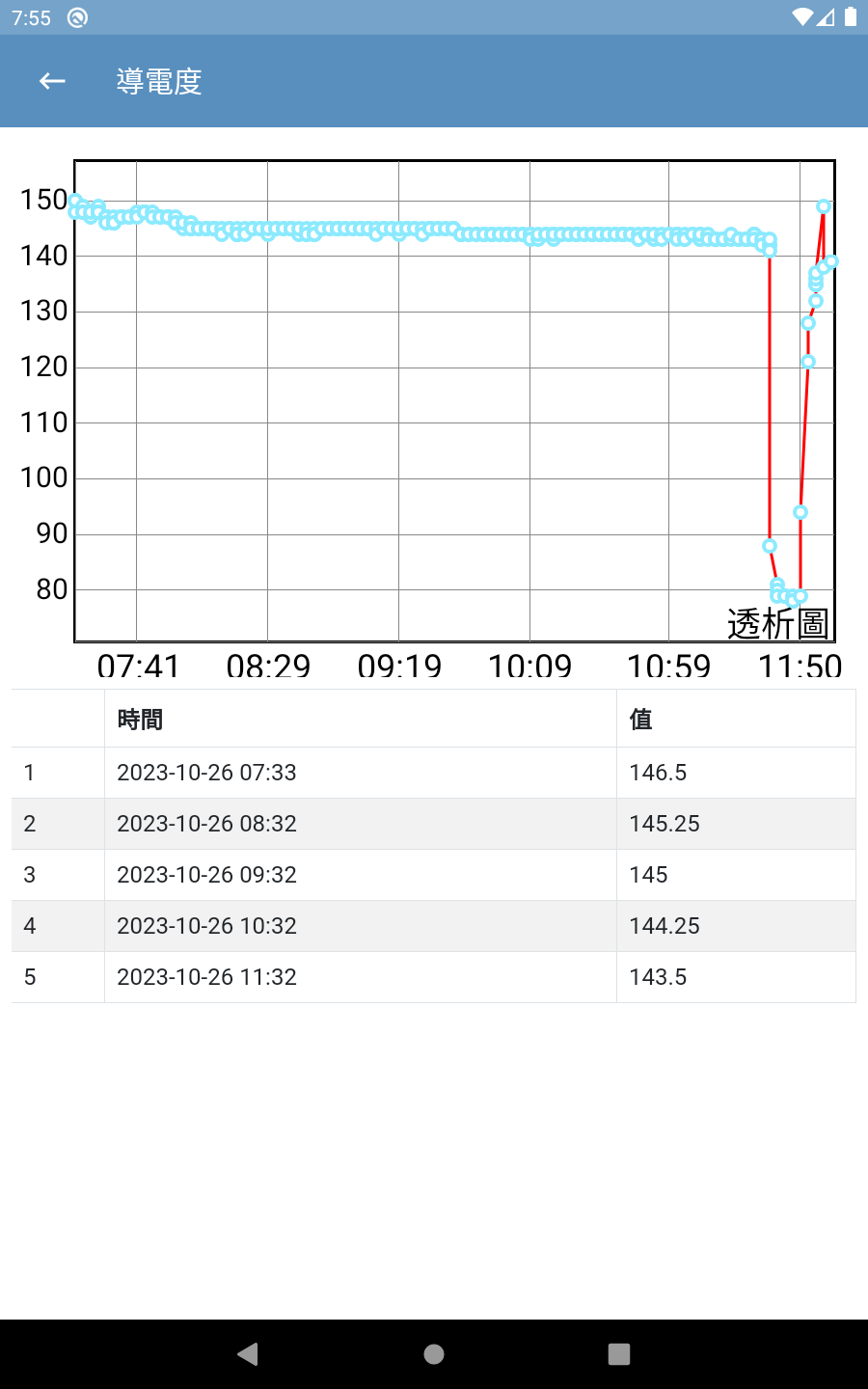
The interfaces of this app were designed according to the needs of the collaborating clinic and allows medical staff to query/view data/graphs and input additional information/data. The UI and user experience (UX) designs were finalized based on extensive communication with the clinic’s medical staff. The main interfaces of the app are shown in Figure 3(a) through Figure 3(d) (Please note that since the proposed system was developed for a local clinic in Taiwan, all interface wording was designed in Traditional Chinese and has not been translated into any foreign languages, including English.). Among them, Figure 3(b) shows the main screen seen by medical staff after logging in via Figure 3(a). It consolidates various relevant entry points, fields, and content according to the clinic’s needs. It is worth noting that although the system collects a wide range of data from the hemodialysis machines to the backend, the main screen only displays the buttons for the items that are of greater interest to physicians (including blood pressure, pulse rate, flow rate, flow volume, achievement rate, venous pressure, transmembrane pressure, dialysate temperature, conductivity, amount of fluid removed, and heparin). Furthermore, if medical staff want to view charts for any specific data item(s), they can simply press the corresponding button, and the app will navigate to display the relevant chart. For example, pressing the Blood Pressure & Pulse Rate button on Figure 3(b) will navigate to the blood pressure & pulse rate chart shown in Figure 3(c); pressing the Conductivity button on Figure 3(b) will navigate to the conductivity chart shown in Figure 3(d); and so on for other data items.
3.4. Design and Implementation: Dedicated Web Interfaces for Medical Personnel
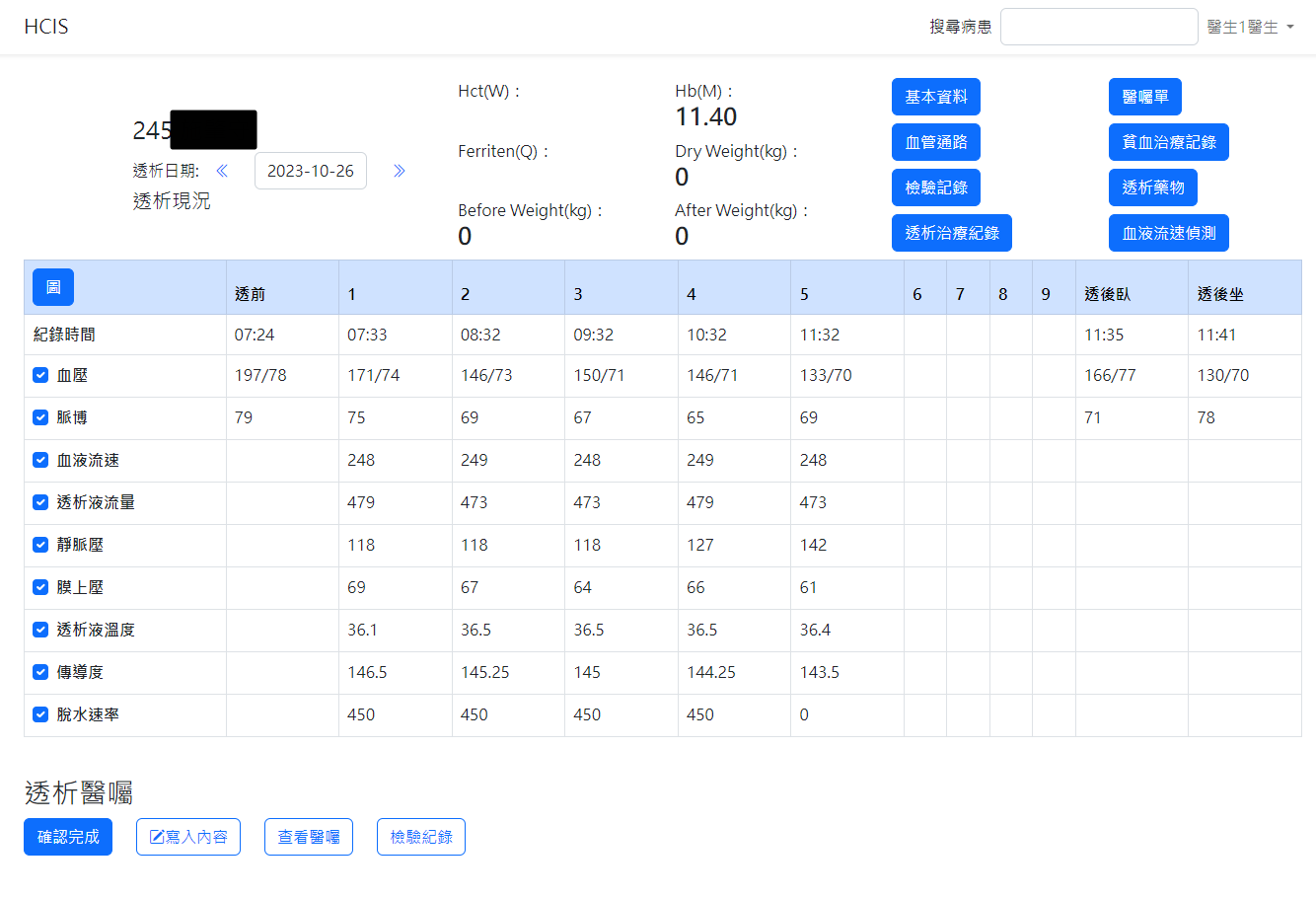
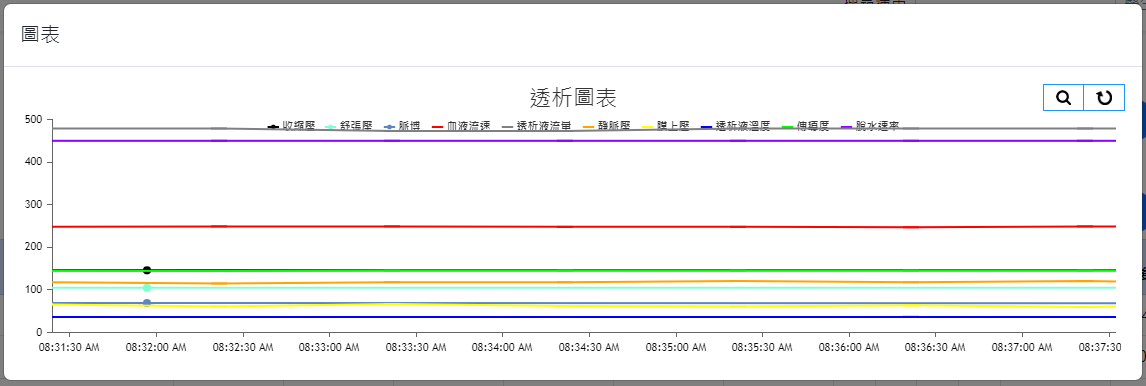
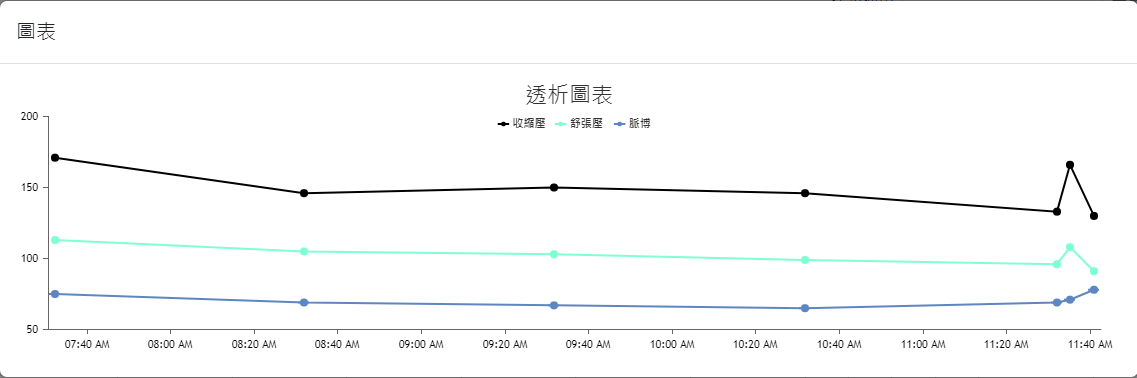
The web interfaces were also designed based on the needs of the collaborating clinic, serving as data query/viewing and other information input interfaces. The overall design prioritizes clarity, simplicity, and alignment with the needs of the clinic’s medical staff. The main interface layouts are shown in Figure 4(a) through Figure 4(h) (Please note that since the proposed system was developed for a local clinic in Taiwan, all interface wording was designed in Traditional Chinese and has not been translated into any foreign languages, including English.). Among them, Figure 4(b) shows the homepage that the medical staff see after logging in via Figure 4(a), which consolidates various relevant entries, fields, and content according to the clinic’s requirements. Again, it is worth mentioning that the system captures numerous data items from the hemodialysis machines to the backend, but the interface only displays items that are of particular concern to the physicians (such as blood pressure, pulse rate, blood flow rate, dialysate flow rate, venous pressure, transmembrane pressure, dialysate temperature, conductivity, and ultrafiltration rate). Additionally, if the medical staff wish to view a line graph of any specific data item(s), they can select the desired item(s) and click the Chart button at the top left of the table, which will display the relevant line graph(s). For instance, if all items are selected in Figure 4(b) and the Chart button is clicked, the interface will display the line graph shown in Figure 4(c). If blood pressure and pulse rate are selected in Figure 4(b) and the Chart button is clicked, the interface will display the line graph shown in Figure 4(d). The rest follow a similar pattern as shown in Figure 4(e) through Figure 4(h). Moreover, since the research requires the collaborating clinic’s medical staff to export de-identified data for analysis and deep learning model training, the staff can select data items and click the Dialysis Treatment Record button (the fourth button on the left column of the eight blue buttons at the top right of the homepage in Figure 4(b)) to export de-identified data for the study to conduct data analysis and deep learning model development, as described in Section 4.
3.5. Design and Implementation: Backend Server
This study utilized the Laravel framework to develop the backend server, and the database was built using MySQL. The core tasks of the backend server are to receive data and store it in the database, as well as to respond to frontend requests for data acquisition from the database via the Web API developed in this research.
4. AI Deep Learning Models for Intradialytic BP/PR Prediction: Training, Evaluation, Comparison, and Recommendation
The deep learning model trained in this study aims to predict the systolic and diastolic blood pressure, as well as the pulse rate, of hemodialysis patients during their dialysis sessions, based on the values of the input variables (features) listed in Table 1 (hereafter referred to as the “BP/PR prediction task”). During each patient’s four-hour dialysis session, a prediction is made every 60 minutes (with feature data collected every minute, and 30 evenly spaced data points selected per hour for each prediction and evaluation). The data used for training, validation, and testing the model were provided as de-identified data by the staff at the collaborating clinic (exported using the proposed system), collected between December 12, 2023, and January 1, 2024. A total of 54,870 data points were gathered from 57 patients who had signed informed consent forms, with 30,864 data points used as the Training Set, 10,288 as the Validation Set, and 13,718 as the Test Set. It is important to note that the execution of this research was conducted entirely under the supervision of the IRB at Mackay Memorial Hospital in Taiwan (IRB no. 21MMHIS375e). The university team was neither able to know nor identify the patients to whom the physiological data corresponded, including their gender and age. Moreover, data privacy was carefully protected, and all data will be destroyed upon the expiration of the data retention period as stipulated by the IRB agreement.
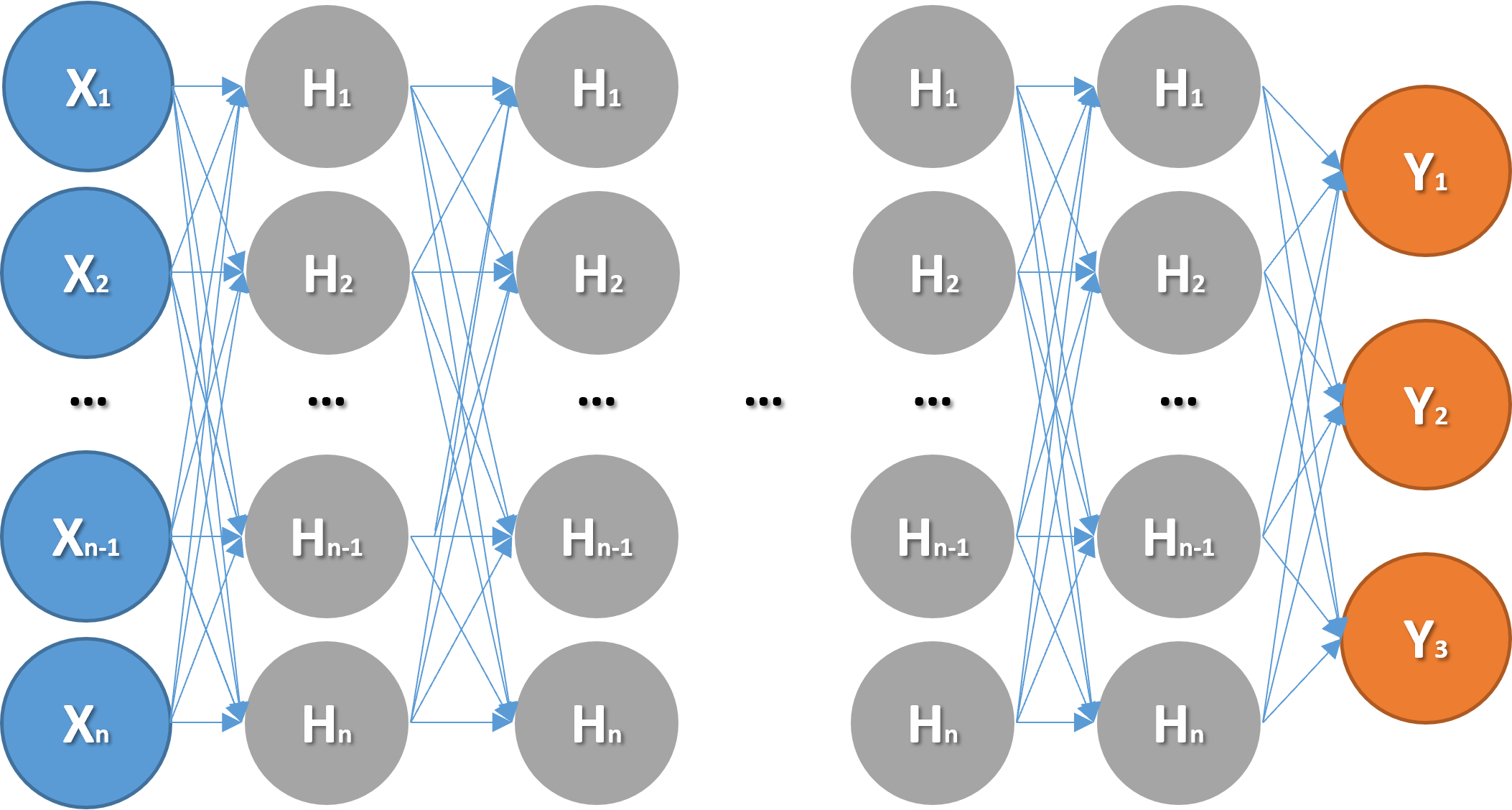
Figure 5(a) and Figure 5(b) respectively illustrate the network architectures of the Artificial Neural Network (ANN) and Long Short-Term Memory (LSTM) models trained in this study. The evaluation of the model output is based on the Mean Absolute Error (MAE) Loss Function. Specifically, the performance of different models, each with varying configurations, parameters, hyperparameters, and network architectures, was assessed by averaging the MAE of the three prediction targets. The following sections provide detailed explanations and recommendations based on these evaluations.
4.1. Investigation of the Activation Functions in the ANN Model
This section compares the performance of ANN models using different activation functions in the BP/PR prediction task for hemodialysis patients. Six activation functions were tested: Scaled Exponential Linear Unit (SELU), SoftPlus, Exponential Linear Unit (ELU), Rectified Linear Unit (ReLU), Leaky ReLU, and Parametric ReLU (PReLU). The evaluation metric used, as previously mentioned, was the loss function based on MAE.
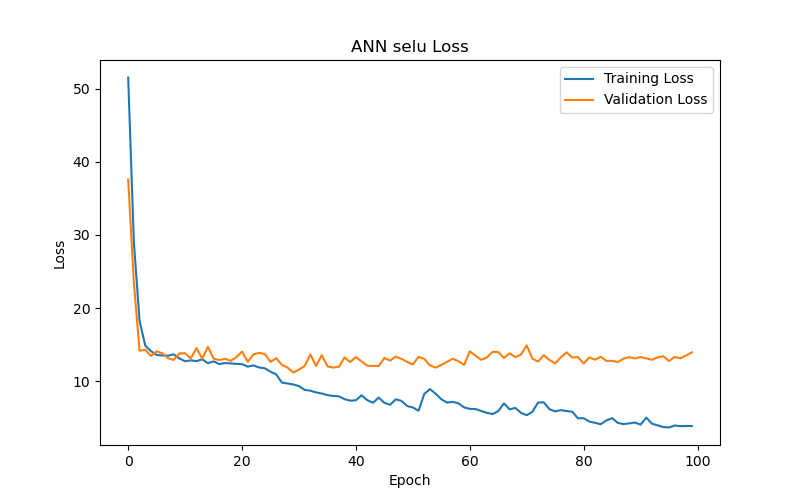
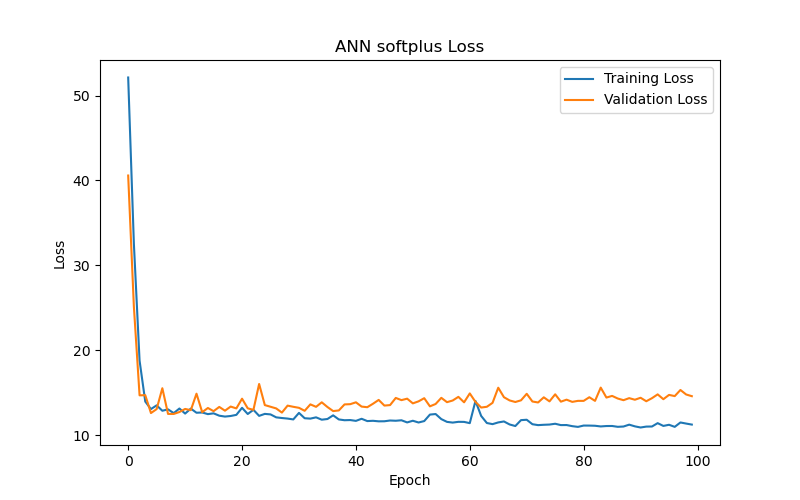
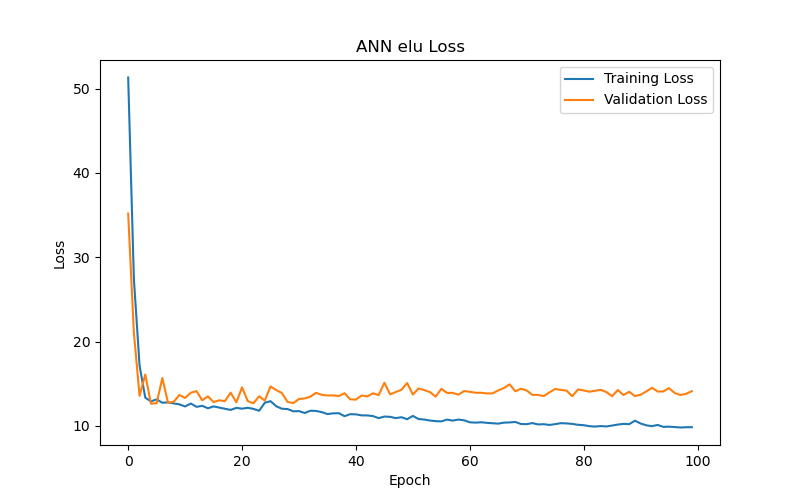
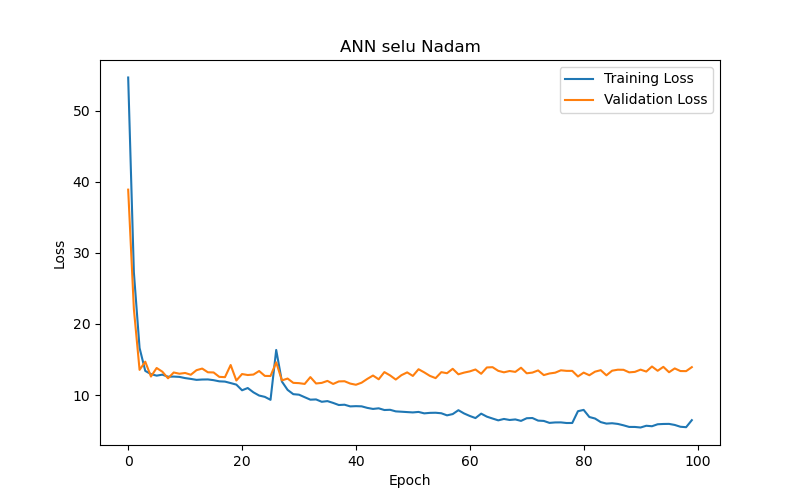
The experimental results (as shown in Table 2 and Figure 6) reveal the following observations: The SELU function (Figure 6(a)) demonstrated the best performance after 50 training epochs (epochs) based on validation loss or validation MAE, with the lowest validation loss/MAE representing the model’s best performance (the same applies hereafter). The optimal test result for this function under the best performance setting, based on test loss or test MAE, with lower test losses/MAEs indicating better test results (the same applies hereafter), was 11.56, making it the best-performing activation function among those tested. In comparison, the SoftPlus and ELU functions (Figure 6(b) and Figure 6(c), respectively) achieved their best performance after fewer epochs (9 and 5, respectively), but their optimal test results (test loss/MAE) under their best performance settings were only 12.59 and 12.82, both of which underperformed compared to the SELU function. This indicates that the SELU function is more advantageous than SoftPlus and ELU for this specific task.
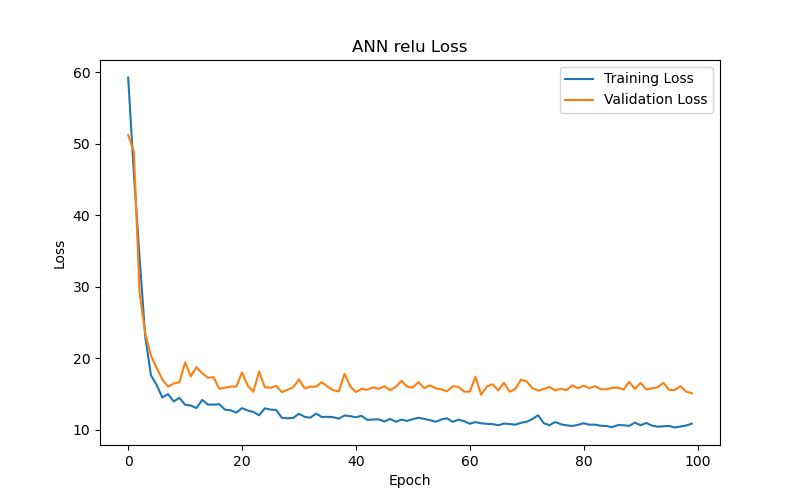
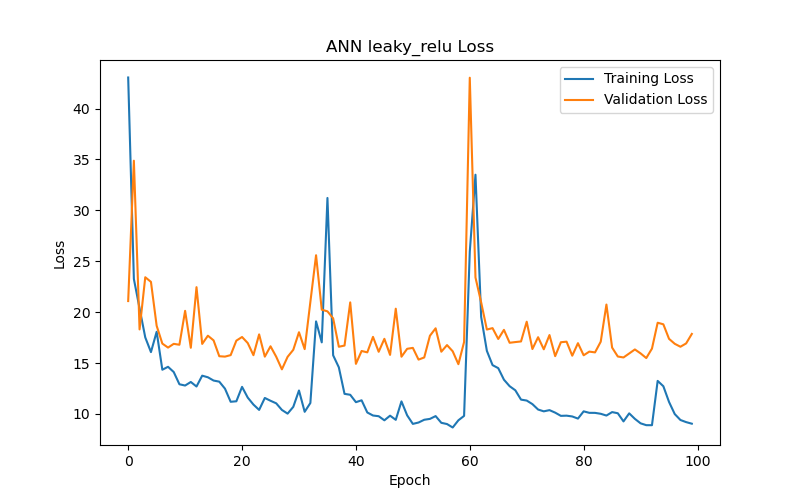
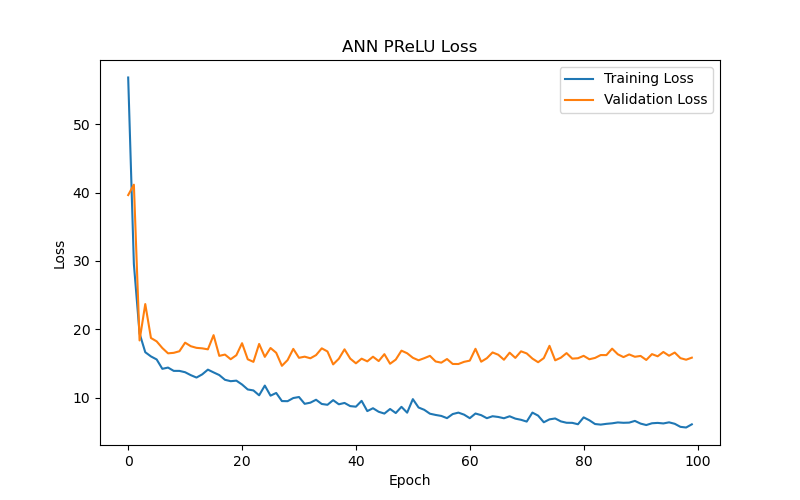
On the other hand, the ReLU function and its two variants, Leaky ReLU and PReLU (Figure 6(d), Figure 6(e), and Figure 6(f), respectively), yielded poorer test results (test loss/MAE) under their best performance settings in this particular task. Notably, the Leaky ReLU function exhibited significant fluctuations during training and validation convergence (see Figure 6(e)). This study investigates the following possible reasons for these fluctuations: it could indicate that the model encountered difficulties during the learning process, or it may suggest that the training data contained outliers, making stable learning difficult. Another possibility is that an excessively high learning rate caused the model to skip over the optimal solution during optimization. Additionally, introducing a small slope in Leaky ReLU to avoid zero gradients and the dying neurons issue when neurons have negative values might lead to instability during training. Although Leaky ReLU achieved its best performance after 28 epochs (with a validation loss/MAE of 14.38), this performance and the corresponding test results (test loss/MAE of 14.21) were still inferior to the first three functions.
It is also worth noting that the training and validation convergence trends (refer to Figure 6) show that the MAE for almost all models dropped rapidly in the initial epochs and then leveled off, suggesting that the ANN models quickly captured the main features of the data, with limited subsequent improvement.
Finally, based on the above analysis, this study recommends using the SELU function as the activation function for ANN models performing BP/PR prediction tasks.
4.2. Investigation of the Numbers of Hidden Layers in the ANN Model
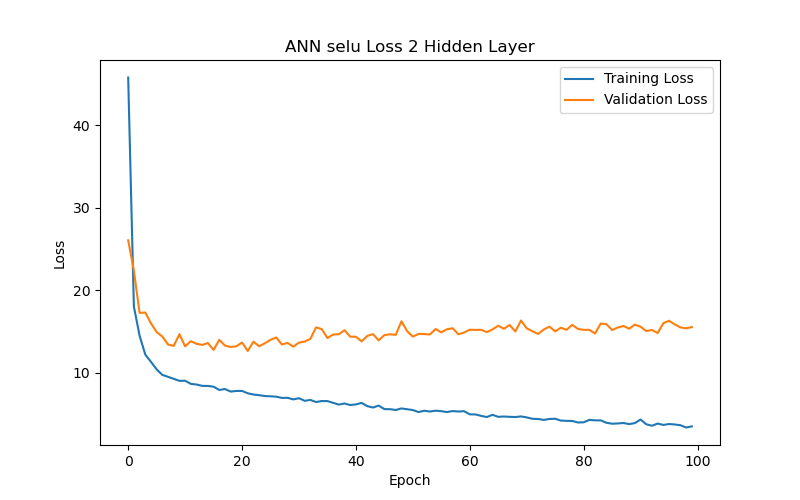
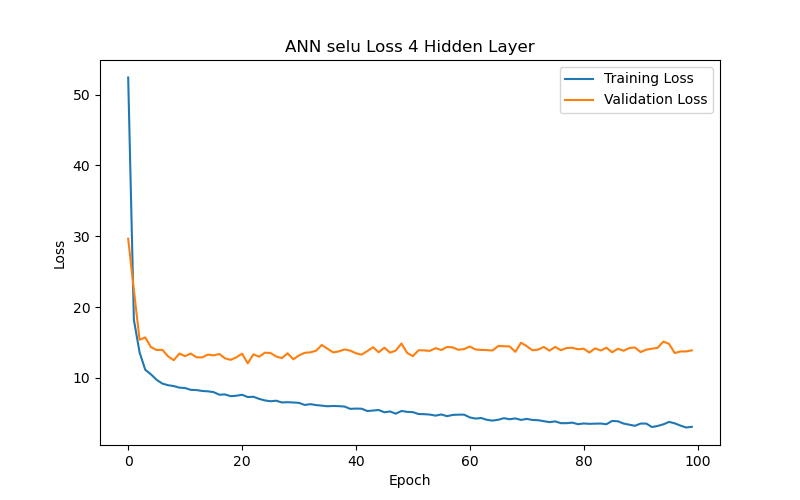
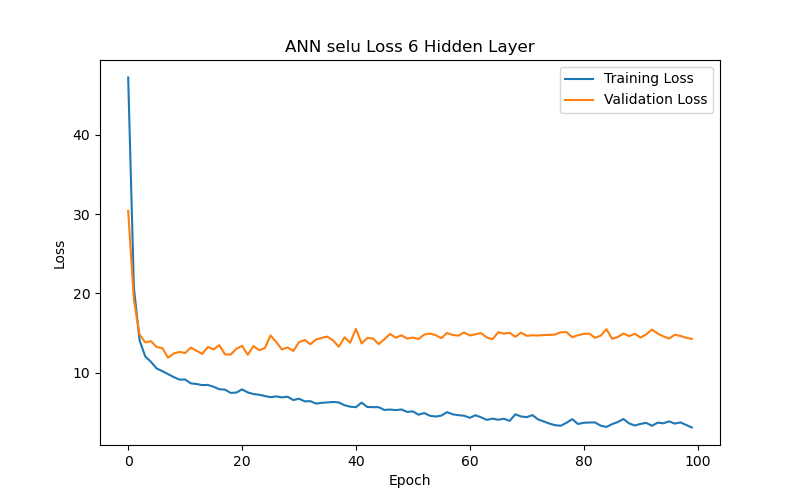
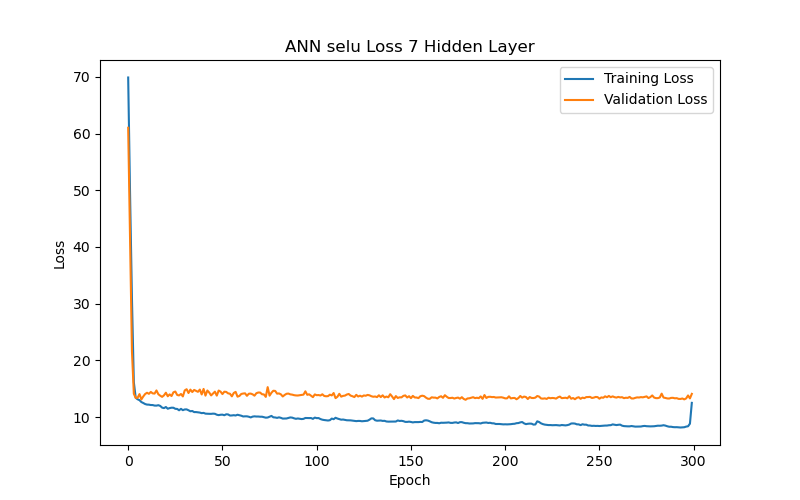
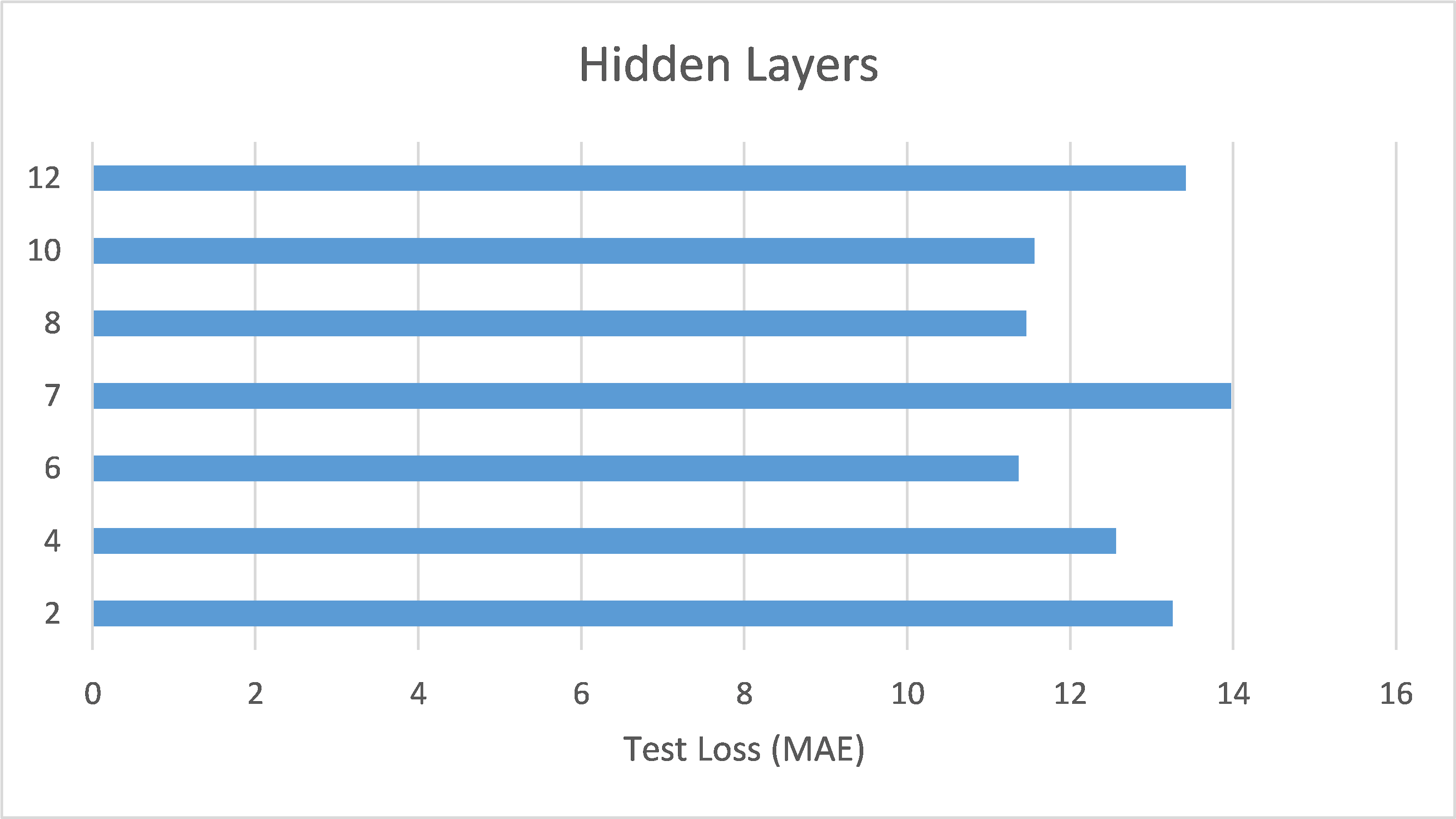
This section further analyzes the impact of different hidden layer numbers on the performance of the ANN model (using the SELU function as its activation function). The layer numbers used were 2, 4, 6, 7, 8, 10, and 12, and the evaluation metric, as previously mentioned, was the MAE-based loss function. From the experimental results (as shown in Table 3 and Figure 7), it can be summarized that the variation in the number of hidden layers significantly affects the model’s generalization ability. When the number of hidden layers increased from 2 to 4 to 6 layers, the model with best performance (based on validation loss/MAE) has gradually decreasing test loss/MAE (indicating better test results), which may suggest that models with more layers between 2 and 6 can capture more complex data correlations. However, when the number of hidden layers reached 7, the model with best performance (based on validation loss/MAE) has increasing test loss/MAE again, which may indicate that the model experienced overfitting during training. Additionally, when the number of hidden layers reached 10, the best validation loss/MAE reached its lowest point, representing the best performance among all layer numbers. This may imply that, for the current dataset, a deeper network architecture (with more layers) between 2 and 10 layers can indeed provide better learning ability, but it also requires more epochs to achieve optimal performance. Finally, when the number of hidden layers increased to 12, the best validation loss/MAE rose again, indicating a decline in model performance. This further suggests that an overly deep network architecture (with too many layers) may not be the best choice for a limited dataset. Therefore, a moderate number of hidden layers (such as 6 or 10 layers) can provide the best predictive results for the BP/PR prediction task in the ANN model without wasting computational resources. To choose between the 6-layer and 10-layer network architectures, further observation of the training/validation convergence of the 6-layer and 10-layer models (as shown in Figure 7(c) and Figure 7(f)) reveals that the error curve for the 10-layer model is relatively less smooth. This may be due to the increased number of parameters in the 10-layer model, leading to a more unstable learning process—such a model would require more data to achieve sufficient training or more refined hyperparameter adjustments to suppress overfitting. Choosing the appropriate number of hidden layers is a decision that requires balancing model complexity, data volume, and available computational resources. Based on this consideration, this study concludes that a six-layer ANN model offers the best performance balance and is the optimal network architecture for the current dataset and computational conditions.
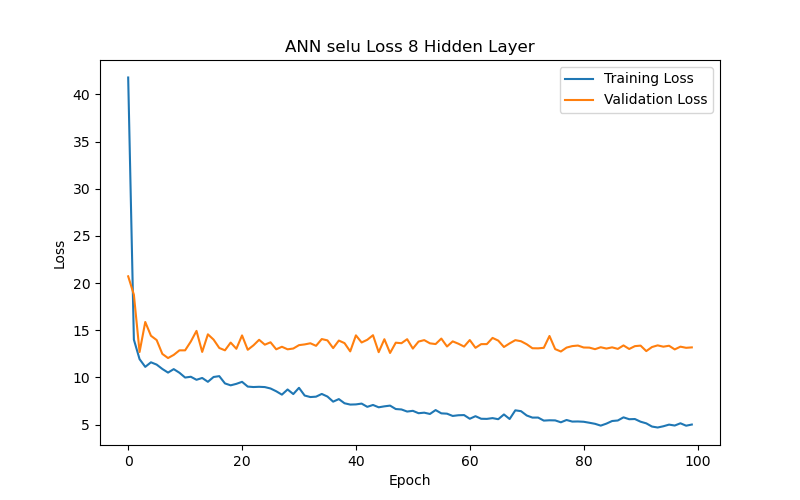
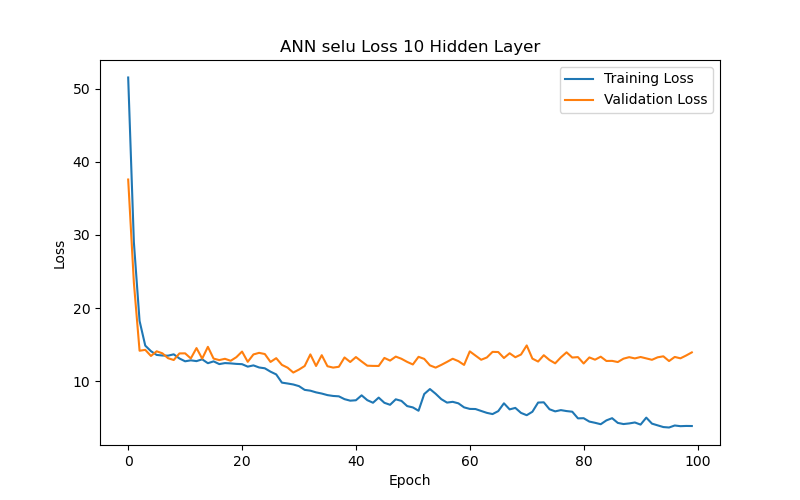
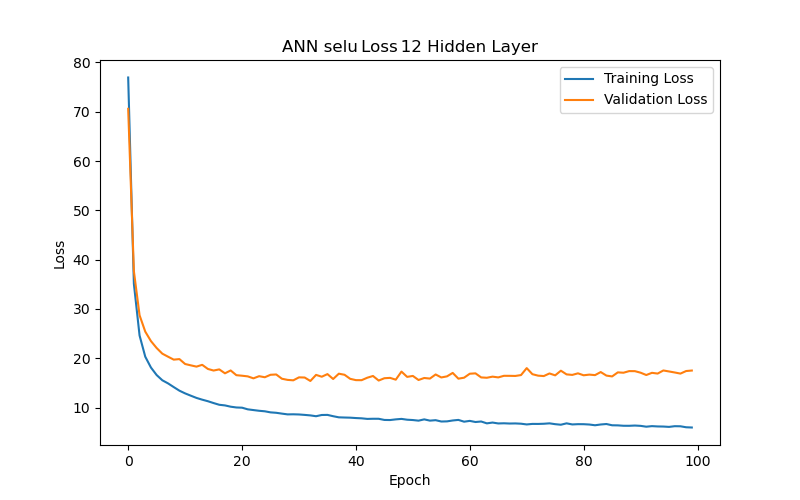
4.3. Investigation of the Input Features in the ANN Model
Based on the results of the previous experiments, this study conducted further experiments using an ANN model with SELU as the activation function and six hidden layers. The experiments focused on different combinations of features listed in Table 1 to assess the impact of different input features on the performance of the ANN model, with the goal of identifying key features. It is important to note that the training and evaluation analyses presented in the previous two sections were conducted using all the features listed in Table 1 (a total of 15). However, this section presents the performance differences in BP/PR prediction tasks when using models trained with four different sets of selected features, aiming to discover the key features for this specific task.
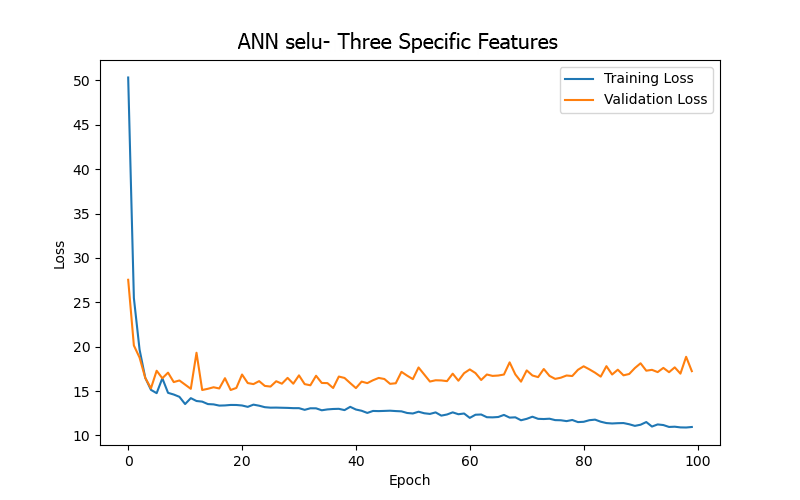
From the experimental results (as shown in Table 4 and Figure 8), it can be summarized that the model trained using only four artery-related features (mean arterial pressure/MAP, systolic blood pressure/BDPS, diastolic blood pressure/BDPL, pulse rate/BDPD) achieved its best performance (based on validation loss/MAE) after 53 epochs, with a test loss/MAE of 11.23, which was the best result among the four sets of input features. This indicates that focusing on artery-related features can yield relatively better prediction results in the BP/PR prediction task, which is consistent with intuitive reasoning.
Next, the model trained using only three features related to blood flow, veins, and dialysis membranes (blood flow rate/BLDF, venous pressure/VEPS, transmembrane pressure/TMP) – which are not directly related to the arteries – showed a significant decline in performance, further reinforcing the significance pointed out by the first feature combination.
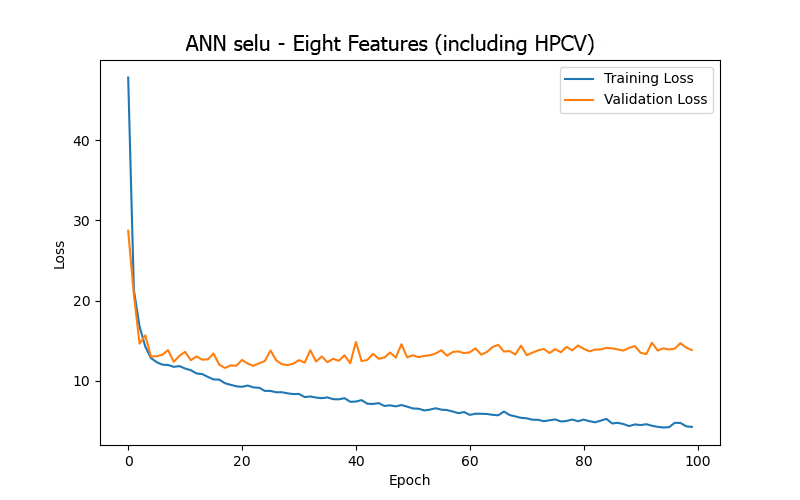
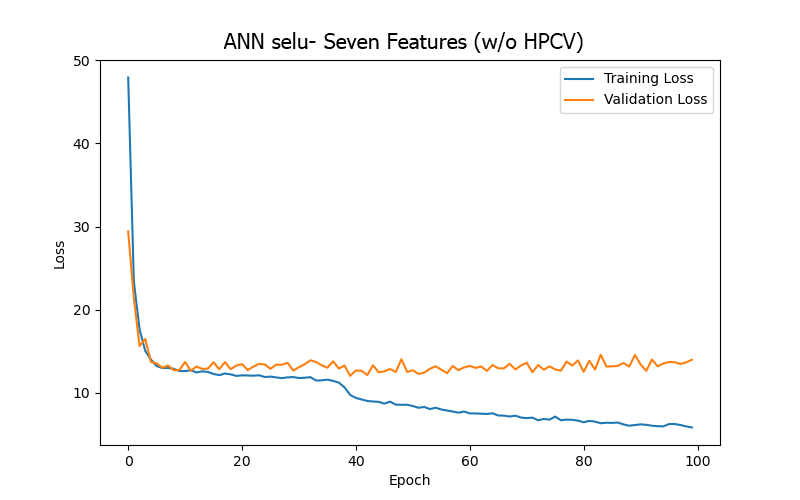
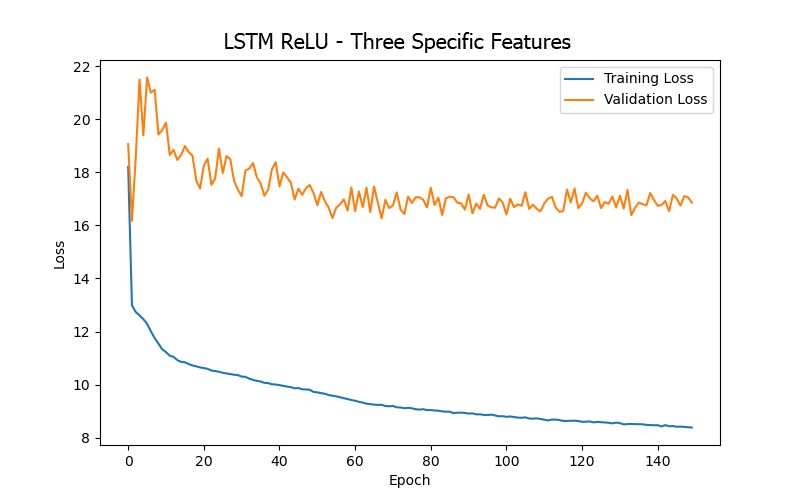
Moreover, after carefully examining the significance of the features and the data content, seven features from the 15 in Table 1 were excluded due to their characteristics of only decreasing over time, lacking direct relevance to blood pressure, or having minimal variation in their data values (ultrafiltration time/UFTM, conductivity/CDCT, dialysate temperature/DLTP, ultrafiltration rate/UFRA, dialysate flow rate/DLFL, heparin infusion rate/HPDR, heparin dose/HPBV). The remaining eight features were then divided into two groups, based on the feature related to thrombus-related cumulative heparin dose (anticoagulant)/HPCV, to conduct experiments: one with eight features (including HPCV) and another with seven features (without or w/o HPCV). The aim was to observe the differences in results depending on whether HPCV was used in training. The model trained using seven features (w/o HPCV) achieved its best performance (based on validation loss/MAE) after 18 epochs, and the test result outperformed that of the model trained using eight features (including HPCV). This may indicate that HPCV did not positively impact the model’s BP/PR prediction task and might have increased model complexity, leading to higher loss.
These results highlight the importance of selecting appropriate features when building prediction models and point to potential directions for further optimizing the model and improving predictive performance. Overall, excluding unnecessary features and focusing only on the four artery-related features can enable the ANN model for the BP/PR prediction task to provide the best results.
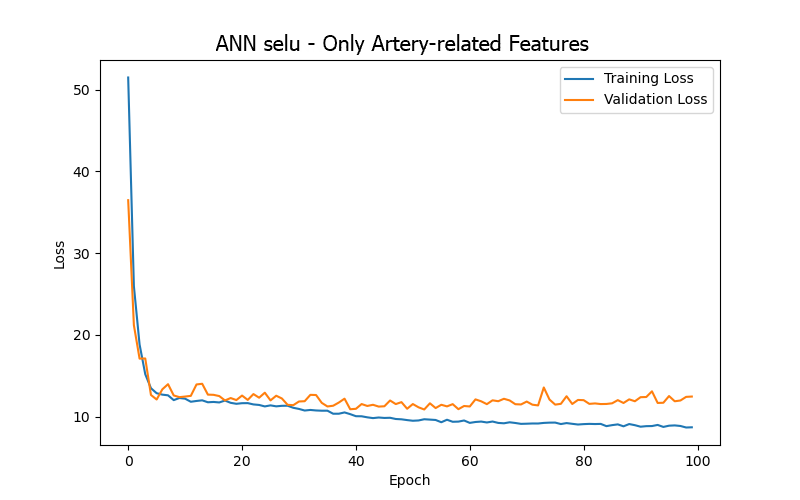
4.4. Investigation of the Input Features in the LSTM Model
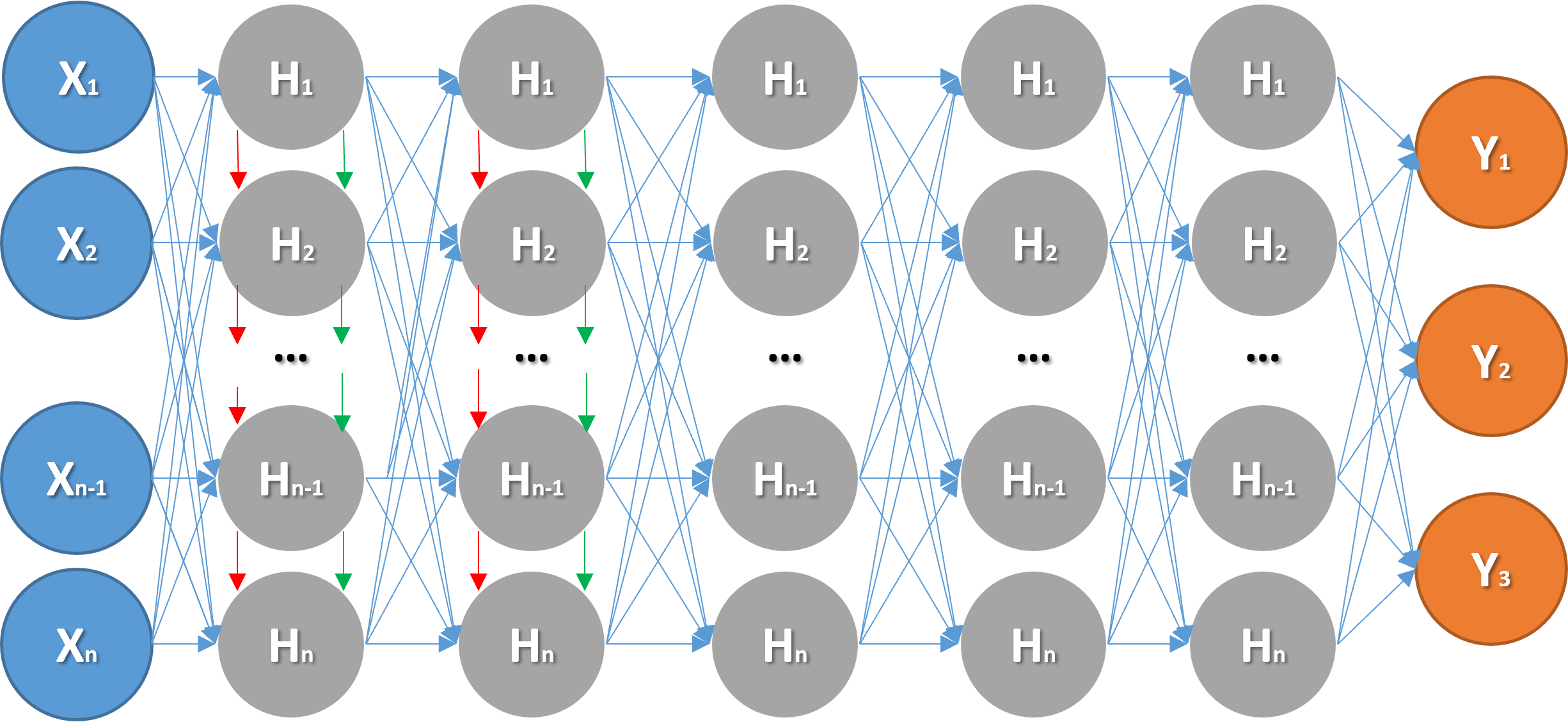
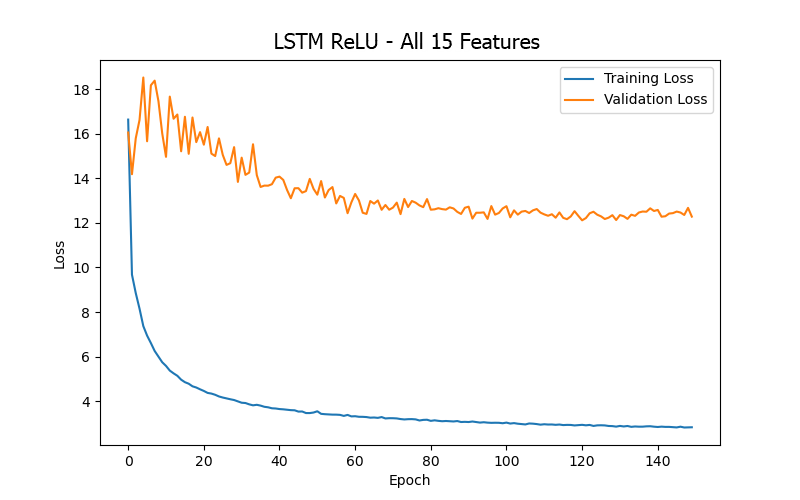
After exploring the performance of the ANN model with different activation functions, hidden layer numbers, and input features in the BP/PR prediction task, this study also investigated the capability of the LSTM model in the same task to compare the performance of different network architectures. The architecture of the LSTM model used in this study can be reviewed in Figure 5 (b), which includes five hidden layers, comprising two LSTM blocks. The ReLU activation function was applied for non-linear transformations, and Dropout layers were used to mitigate overfitting.
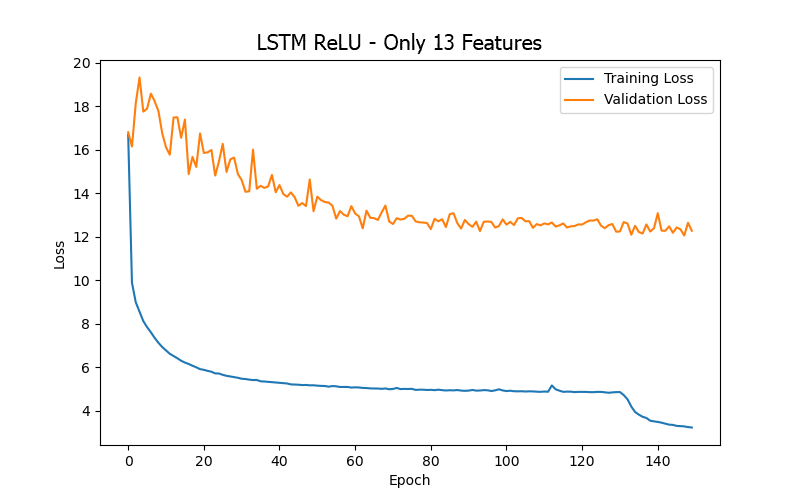
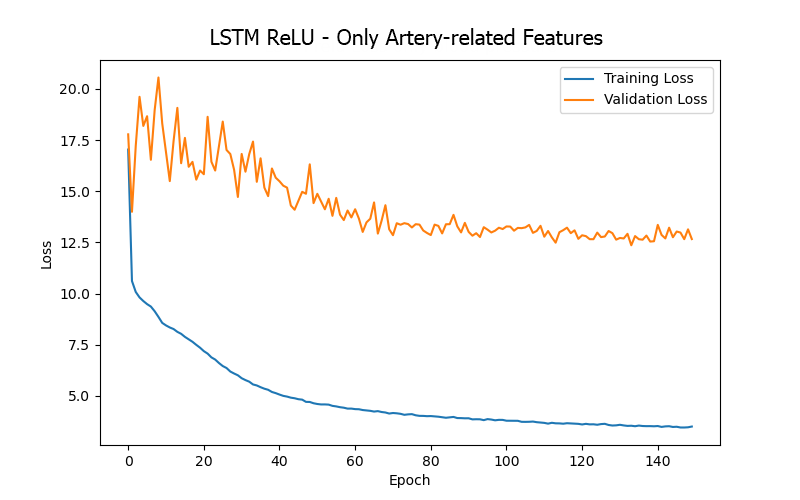
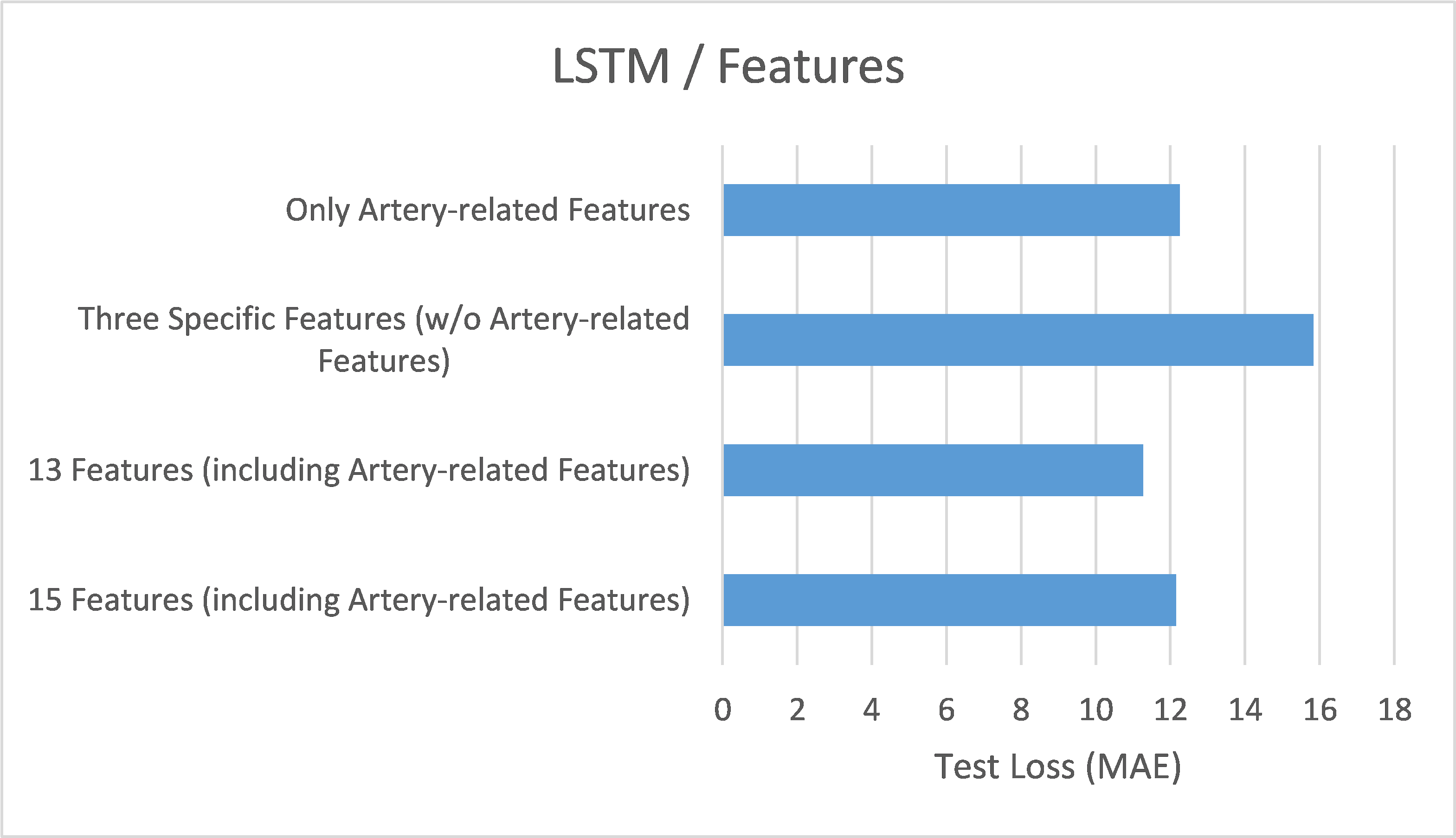
From the experimental results (as shown in Table 5 and Figure 9), it can be summarized that when training the LSTM model for the BP/PR prediction task, the input features that included the four artery-related features (mean arterial pressure/MAP, systolic blood pressure/BDPS, diastolic blood pressure/BDPL, pulse rate/BDPD) provided better performance (based on validation loss/MAE). This can be observed by comparing the top three data rows (all including the four artery-related features) and the last row (excluding any artery-related features) in Table 5, as well as the significantly higher error values in Figure 9(d) (excluding any artery-related features), indicating that artery-related features are crucial for accuracy in the BP/PR prediction task, as was also inferred from the ANN model results and intuitive reasoning.
Furthermore, when comparing the 15 input features (first row in Table 5), 13 input features (second row in Table 5), and four input features (third row in Table 5), it was found that using 13 input features provided the best test result (i.e., the lowest test loss/MAE). This seems to suggest that including too many features that do not intuitively affect the prediction target (15 features vs. 13 features) only introduces noise during LSTM model training (like what was observed with the ANN model). However, for the LSTM model, including more features related to the hemodialysis process (rather than focusing solely on the four artery-related features, 13 features vs. 4 features) clearly yielded better result, which differs from the observations made with the ANN model. This could be due to the different sensitivities of the two models to various data during learning.
Finally, when directly comparing the LSTM and ANN models (as shown in Table 6), it was found that when using only the four artery-related features (mean arterial pressure/MAP, systolic blood pressure/BDPS, diastolic blood pressure/BDPL, pulse rate/BDPD) as input features, the ANN model produced better test results than the LSTM model. This may indicate that although the three targets predicted by the models (systolic blood pressure, diastolic blood pressure, pulse rate) have temporal dependencies, the time span is not very long (only four hours—the duration of a patient’s hemodialysis session) and therefore the LSTM model (which typically performs better when the prediction targets have long-term temporal dependencies) did not outperform the ANN model. However, the best test result of the LSTM model (using 13 features, with a test loss of 11.28) were not significantly different from that of the ANN model (using four artery-related features, with a test loss of 11.23). Furthermore, when comparing the training loss between the two models (as shown in Table 7), the LSTM model generally had lower training loss than the ANN model, which might suggest that the LSTM model has a better learning effect.
(a)
(b)
(c)
(d)
4.5. Investigation of the Optimizers in the ANN Model
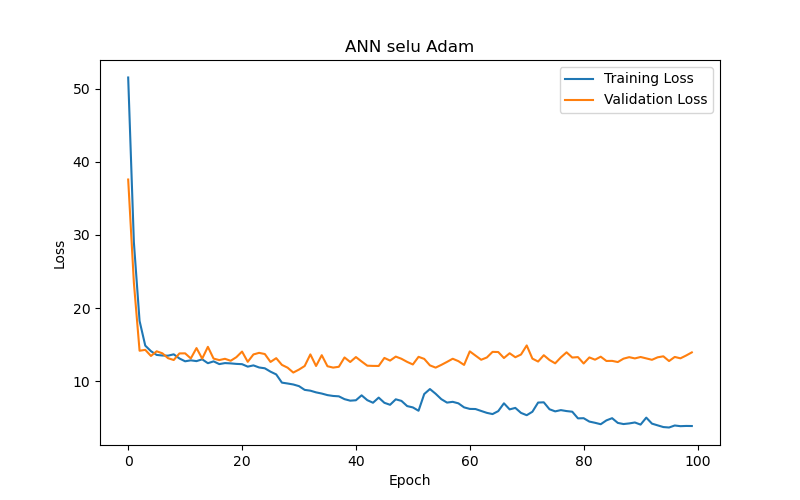
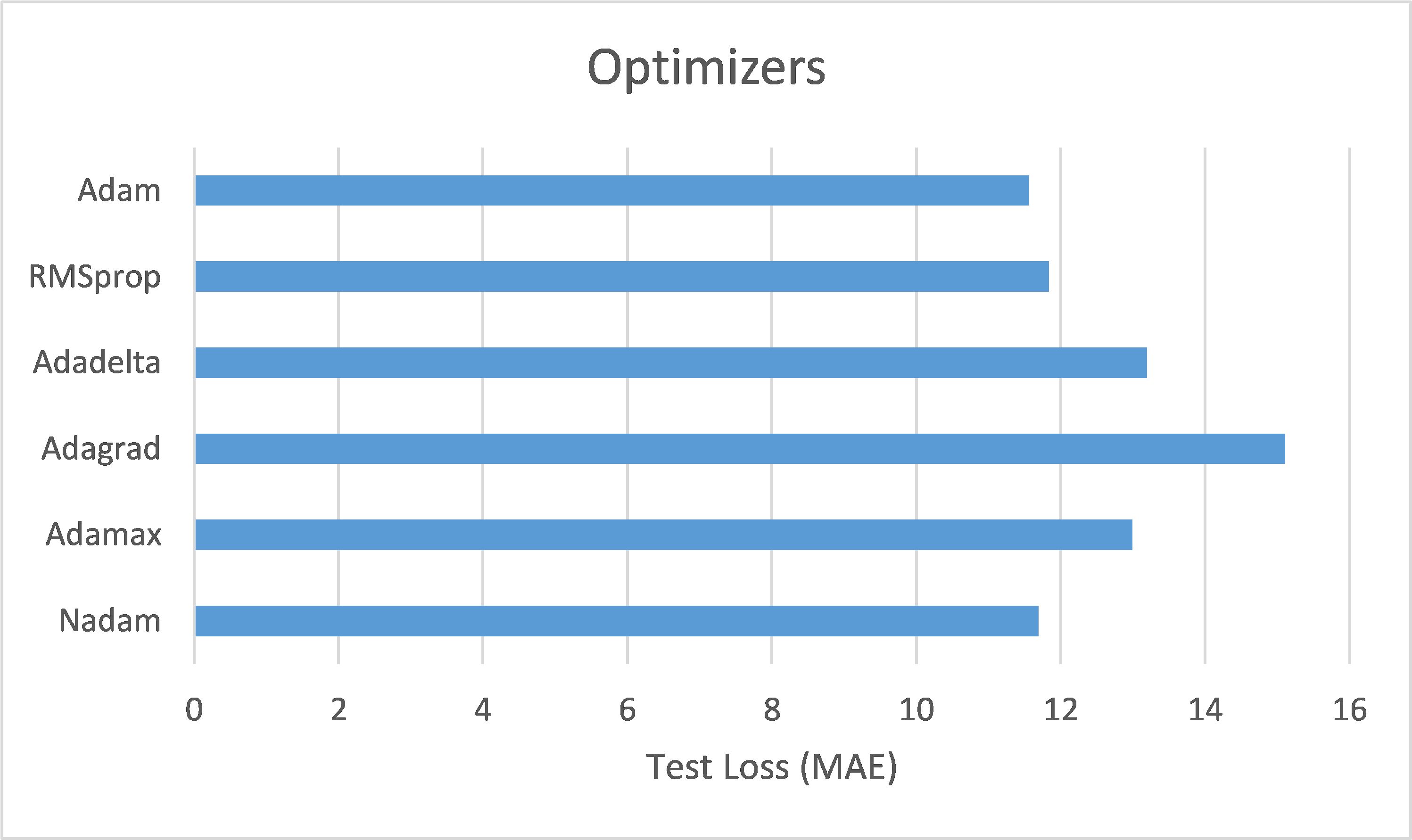
This study also compared the impact of various optimizers on the performance of an ANN model (using SELU activation with 10 hidden layers) in the task of BP/PR prediction. The experimental results (as shown in Table 8 and Figure 10) summarized that, among the six optimizers—Adam, RMSprop, Adadelta, Adagrad, Adamax, and Nadam—Adam and Nadam produced the best test results under the best-performance condition (based on validation loss/MAE). Specifically, Adam reached its optimal performance (the lowest validation loss/MAE) after 30 epochs, demonstrating its advantages in rapid convergence and accurate prediction. Therefore, for ANN models tasked with BP/PR prediction, this study recommends using the Adam optimizer.
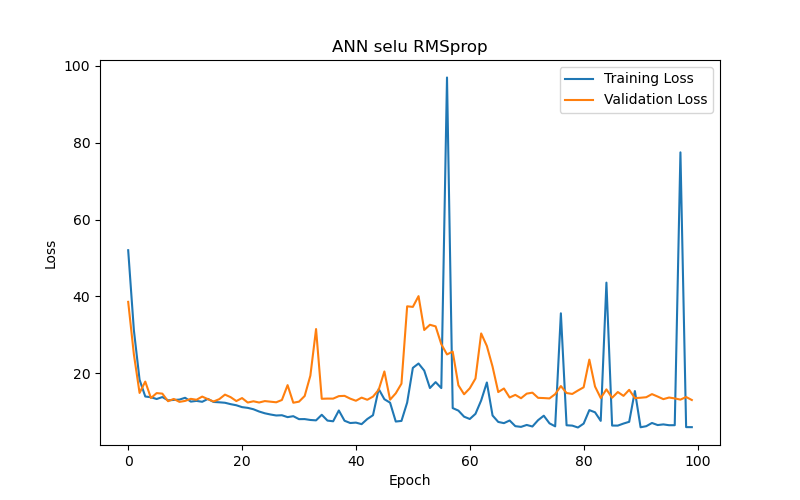
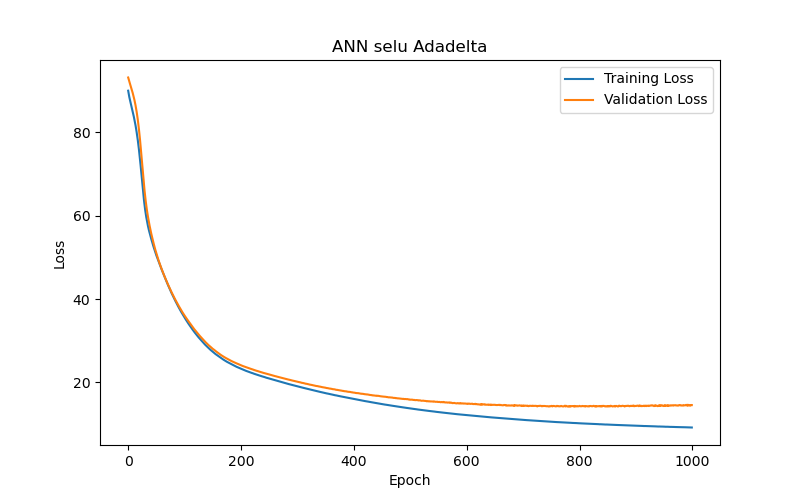
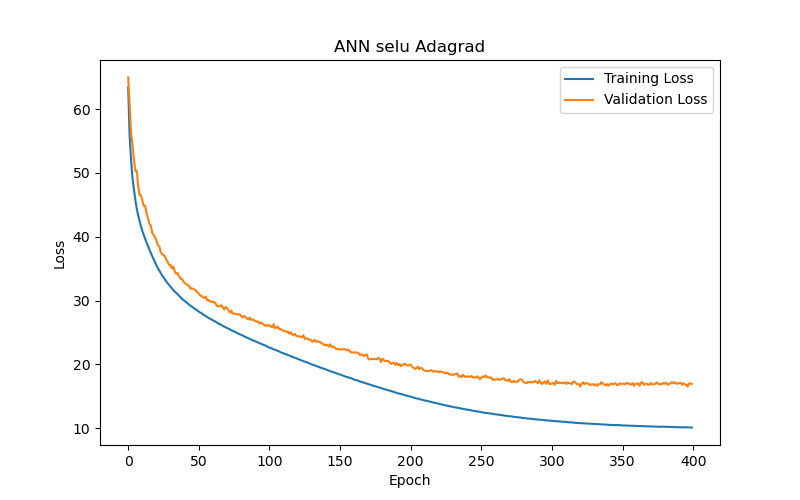
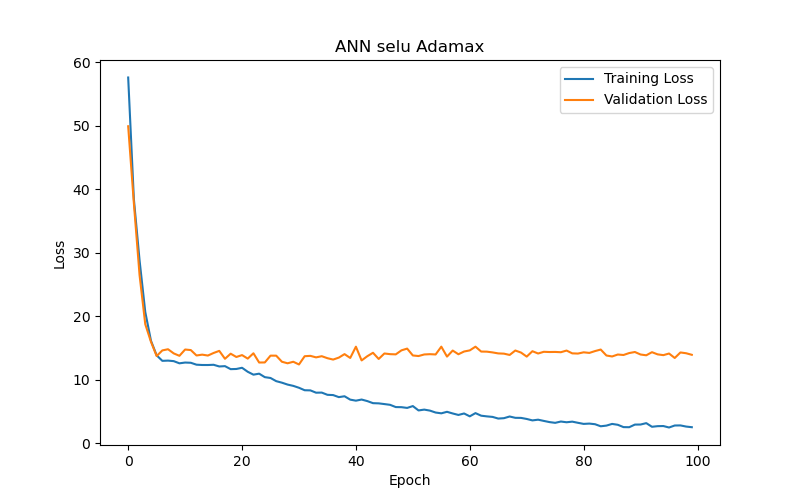
4.6. Summary
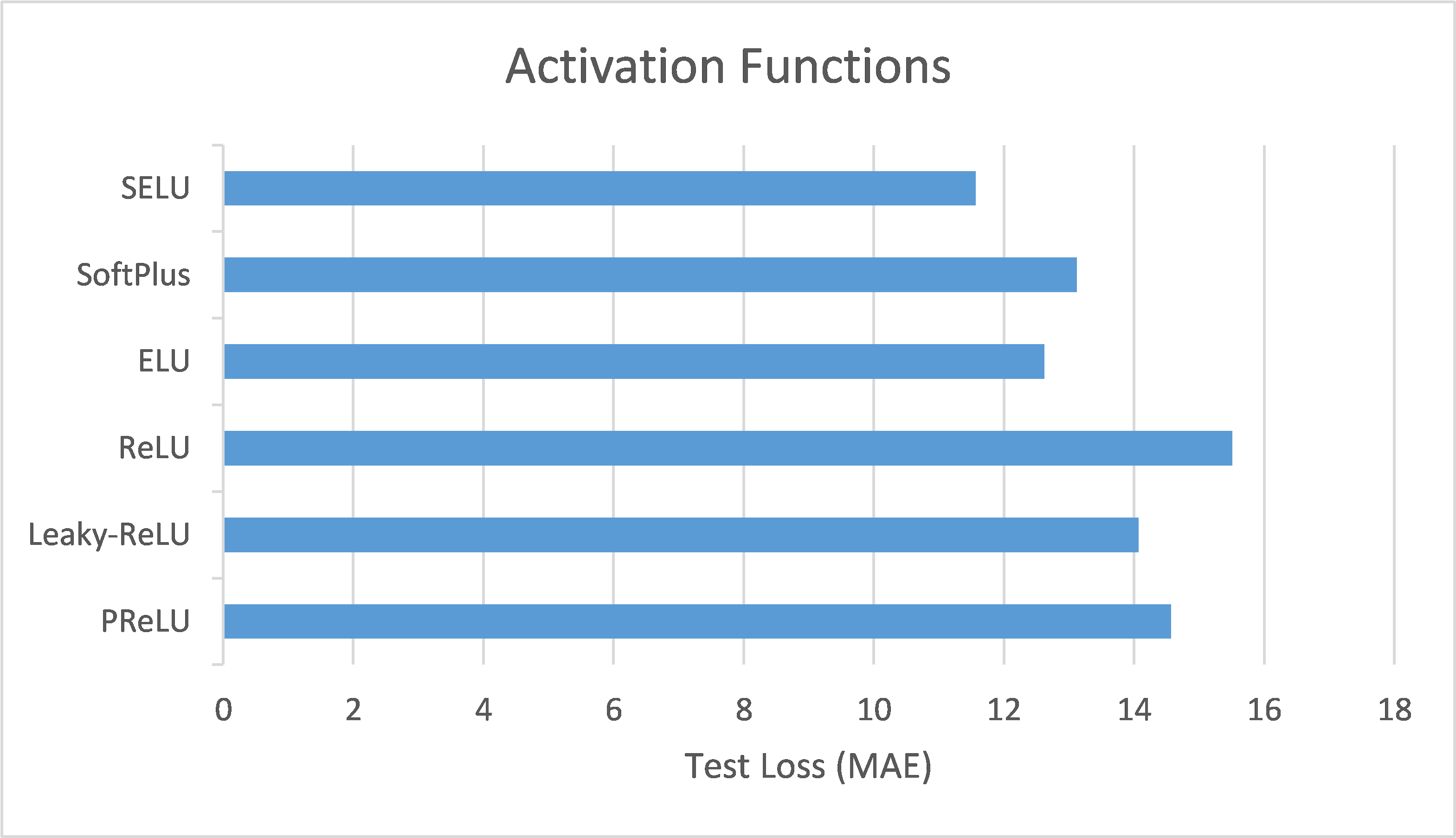
This section reviews and summarizes the main findings of the experiments discussed earlier. First, in the activation function experiments, the study found that the choice of activation function significantly impacts the training speed and accuracy of the model. Among the six functions tested, the ANN model using the SELU function as the activation function provided the best test results, as shown in Figure 11(a). Next, in the hidden layer number experiments, different numbers of hidden layers were used to train the ANN model. It was found that increasing the number of hidden layers can improve the model’s learning ability; however, too many layers can lead to overfitting and decreased training efficiency. Thus, neither too few nor too many hidden layers are ideal—only an appropriate number of layers can provide the best test results. The study found that for the BP/PR prediction task, the ANN model with six hidden layers provided the best test results, as shown in Figure 11(b). Furthermore, in the feature selection experiments for the ANN model, different feature combinations were used for training, revealing that the absence of artery-related features resulted in poor outcomes. The best test results were obtained with a combination containing only four directly artery-related features, as shown in Figure 11(c). This aligns with the intuitive assumption that artery-related features have a critical impact on the BP/PR prediction task, underscoring the importance of selecting appropriate input features to enhance model performance. Feature selection is indeed necessary.
For comparing different network architectures, the study also conducted feature selection experiments with the LSTM model. It was observed that training the LSTM model took significantly longer than the ANN model, and its test results were slightly inferior to those of the ANN model (refer to Table 6). This may be because, although the three target variables being predicted have temporal dependencies, the duration is not very long (only four hours), leading to the LSTM model’s test results being slightly less favorable than those of the ANN model, where the LSTM model typically performs better when the prediction targets have long-term temporal dependencies. Comparing the training loss of both models (refer to Table 7), the LSTM model generally exhibited lower training loss than the ANN model, which may indicate that the LSTM model has a better learning effect. Regarding feature selection for the LSTM model, the study also tested combinations excluding artery-related features, with similarly poor results, echoing the findings from the ANN model. Moreover, removing features that theoretically should not affect the prediction targets (i.e., noise) resulted in the best test outcomes, as shown in Figure 11(d).
Lastly, in the optimizer experiments for the ANN model, six different optimizers were used to train the model, and it was found that the choice of optimizers significantly impacted the model’s performance. The Adam and Nadam optimizers provided some of the best test results, as shown in Figure 11(e), and generally converged quickly with high accuracy. To conclude, the study offers the following recommendations: Considering the constraints of computational resources and data volume, a six-layer ANN model with SELU activation and Adam optimizer is recommended for hourly intradialytic BP/PR prediction tasks. The input features should focus on the four key factors directly related to arterial conditions. These findings are shared with the belief that they will provide guidance for future predictive model development on similar datasets.

5. Conclusions
5.1. Concluding Remarks
This study is a tripartite collaborative project conducted by our university team in partnership with an enterprise and a hemodialysis clinic. The project involved the development and implementation of a customized IoT Information System designed specifically for the clinic’s hemodialysis machines, as well as the analysis of de-identified data provided by the clinic through this system to build AI deep learning predictive models. The IoT information system developed under objective one of this project aids the clinic by automating the collection of clinical hemodialysis machine data, digitizing data storage, and offering an informative interface for easy human-machine interaction (HMI), data access (including querying and input), and graphical data display. This system replaces traditional manual paper-based recording and storage methods, significantly enhancing the overall efficiency of the clinic’s hemodialysis services. Consequently, healthcare professionals can focus their time and energy more effectively on their clinical duties, without the distraction of cumbersome paper-based tasks. Furthermore, the system’s data visualization capabilities, presented through web and app interfaces, allow clinic staff to intuitively and promptly grasp patients’ conditions during dialysis, facilitating efficient decision-making and related interventions. The digitized data stored within the system also enables physicians to conduct future analyses, gain valuable insights into dialysis treatment, and provide precise clinical care for individual patients. On the other hand, the completion of objective two of this project – training, evaluation, comparison, and recommendation of AI deep learning models for predicting intradialytic BP/PR – is expected to contribute to the collaborating clinic and the broader medical informatics research community.
Regarding the IoT information system for the first project objective, the system has been successfully implemented at the collaborating clinic. This system utilizes IoT and ICT for its development and consists mainly of transmission bridges, a web interface and app for healthcare professionals, and a backend server. It provides two primary functions: (1) access, data format conversion, transfer, and storage of hemodialysis data, and (2) viewing of data and charts by healthcare professionals and input of additional relevant information. The transmission bridges, as IoT devices, collect data from the hemodialysis machine’s Ethernet port, transform the data format, and forward the data to the backend server for storage. The web interface and app, designed based on the clinic’s specific needs, allow healthcare professionals to view relevant dialysis data and charts, as well as input various specific information and data. The backend server includes a web API, a website, and a database, collecting and storing data and information transmitted from the transmission bridges, web interface, and app, and providing the data and information requested by the web and app.
For the second project objective, this study used de-identified data exported (via the proposed system) and provided by the clinic to train, evaluate, compare, and analyze AI deep learning models for predicting BP and PR during dialysis. Based on the detailed content presented in Chapter 4, the study provides the following recommendations: Given the limitations of computational resources and data volume, for an hourly BP/PR prediction task, a six-layer (hidden layers) ANN model is recommended, with SELU as the activation function and Adam as the optimizer. The input features should include four features directly related to arterial conditions. This approach should yield optimal results for the intradialytic BP/PR predictive models. Note that both objectives were completed under the supervision of the IRB at Mackay Memorial Hospital in Taiwan (IRB no. 21MMHIS375e).
5.2. Future Work
In terms of future development, the following are some feasible directions:
- Clinic Staff Feedback Collection and UI/UX Optimization: Future work could involve systematically collecting user feedback and suggestions for improvement from clinic staff to further refine the system’s interface design. This iterative process would aim to enhance the overall UI/UX, thereby improving system usability and workflow integration for clinical personnel.
- Patient Engagement: Future enhancements could include adding patient or family member accounts, allowing patients or their relatives to log into the clinic’s information system to access personal dialysis information. This would enable them to actively participate in nursing and dialysis decision-making processes. This could involve developing patient/family-friendly web interfaces and app that make it easy for patients or their families to query and understand their related data.
- Expanding Collaborations: Through recommendations and matchmaking facilitated by the collaborating enterprise and clinic, additional government funding could be pursued to customize and develop similar IoT-based information systems for other dialysis specialty clinics. This approach would benefit resource-constrained clinics within Taiwan’s tiered healthcare system, enabling broader access to these innovations and improving care for more dialysis patients. Moreover, expanding collaboration with additional hemodialysis clinics would allow for the collection of a more diverse dataset, thereby enhancing the predictive model and improving its generalizability across different clinical settings.
- Training and Evaluating Other Deep Learning Predictive Models: Although the LSTM model, which was expected to perform better, was slightly inferior to the ANN model as analyzed in Chapter 4, the university team remains curious about this phenomenon and looks forward to further investigation. Additionally, attempts could be made to train BLSTM models and compare their results with those of the other two models.
- Model Interpretability: In the future, this work may incorporate interpretive techniques, such as Shapley Additive Explanations (SHAP) or Local Interpretable Model-Agnostic Explanations (LIME), to enhance the transparency and comprehensibility of the predictive models. These methods would enable clinicians to better understand the model’s decision-making process and foster greater trust in its clinical applicability.
Overall, the mid-to-long-term outlook of this research is to continue participating in the development of the medical informatics field. By engaging in cross-disciplinary practical collaborations in the medical and IT sectors, the goal is to enhance the service efficiency of related medical institutions and ultimately provide better care quality for patients.
Author Contributions: Conceptualization, I-H.; methodology, I-H.; software, C.-K. and I-H.; validation, I-H. and C.-K.; formal analysis, I-H. and C.-K.; investigation, I-H. and C.-K.; resources, I-H. and C.-K.; data curation, C.-K.; writing—original draft preparation, C.-K.; writing—review and editing, P.-C.; visualization, C.-K.; supervision, I-H.; project and research administration, I-H.; funding acquisition, I-H. All authors have read and agreed to the published version of the manuscript. It should be noted that the author P.-C. is not involved in the research itself, including the processing of all the clinical data related to this study, in compliance with the IRB agreement (IRB no. 21MMHIS375e). P.-C.’s role is limited to handling IRB and NSTC administrative tasks, such as documentation and correspondence, as well as the review, editing, and refinement of this journal paper.
Funding: This research was funded by National Science and Technology Council (NSTC), grant numbers 110-2622-E-159-005, 109-2622-E-159-004, 108-2622-E-159-002-CC3, 109-2813-C-159-004-E, 112-2813-C-159-008-H, and 109-2635-E-159-002, as well as Yuan-Ching International Co., Ltd.
Data Availability Statement: The data used for training, validation, and testing the model were provided as de-identified data by the staff at the collaborating clinic (exported using the proposed system), collected between December 12, 2023, and January 1, 2024. A total of 54,870 data points were gathered from 57 patients who had signed informed consent forms, with 30,864 data points used as the Training Set, 10,288 as the Validation Set, and 13,718 as the Test Set. It is important to note that the execution of this research was conducted entirely under the supervision of the IRB at Mackay Memorial Hospital in Taiwan (IRB no. 21MMHIS375e). The research team at the university was neither able to know nor identify the patients to whom the physiological data corresponded, including their gender and age. Moreover, data privacy was carefully protected, and all data will be destroyed upon the expiration of the data retention period as stipulated by the IRB agreement.
Conflicts of Interest: The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- National Kidney Foundation. “GFR (Glomerular Filtration rate) - A Key to Understanding How Well Your Kidneys Are Working.” Available online: https://www.kidney.org/sites/default/files/docs/11-10-1813_abe_patbro_gfr_b.pdf (accessed on 25 Jul. 2024).
- National Kidney Foundation. “Hemodialysis.” Available online: https://www.kidney.org/atoz/content/hemodialysis (accessed on 25 Jul. 2024).
- Batley, G.E.; Apte, S.C. Elemental speciation | waters, sediments, and soils. In Encyclopedia of Analytical Science, 2nd ed.; Worsfold, P., Townshend, A., Poole C., Eds.; Elsevier, 2005; pp. 481–488.[CrossRef]
- National Library of Medicine – National Center for Biotechnology Information. “Hemodialysis.” Available online: https://www.ncbi.nlm.nih.gov/books/NBK563296/ (accessed on 25 Jul. 2024).
- Taiwan Association for Medical Informatics. Available online: http://www.medinfo.org.tw/html/intro_eng.html (accessed on Jul. 25, 2024).
- Peng, I.H.; Tien, C.K.; Lee, P.C.; Chen, X.E. An IoT-based data collection and digitalized storage system for Hemodialysis machines. In the Proceedings of 2023 the Third Minghsin University of Science and Technology – Engineering, Technology, and Application Conference, Dec. 2023; pp. 514–519.
- Peng, I.H.; Tien, C.K.; Lee, P.C.; Chen, X.E. An IoT-based data collection and clinical information dashboard system for Hemodialysis machines. In the Proceedings of 2024 Wireless, Ad-hoc, and Sensor Networks Conference (WASN 2024), Aug. 2024.
- Cai, D.S. An Initial Study of Using Big Data Analysis to Explore Intradialytic Hypotension and Ultrafiltration. Master's Thesis, National Cheng Kung University, Tainan, Taiwan, 2019.
- Taipei Veterans General Hospital. Available online: https://www.vghtpe.gov.tw/News!one.action?nid=7753 (accessed on 8 Aug. 2024).
- Wang, G.; Song, S. Dialysate decision support method based on deep learning. In the Proceedings of 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Jun. 2020; pp. 522–526.[CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks 2005, Vol. 18, No. 5–6, pp. 602–610.[CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; et al. Attention is all you need. Advances in Neural Information Processing Systems 2017, pp. 5998–6008.
- Barbieri, C.; Cattinelli, I.; Neri, L.; et al. Development of an artificial intelligence model to guide the management of blood pressure, fluid volume, and dialysis dose in end-stage kidney disease patients: proof of concept and first clinical assessment. Kidney Diseases 2019, Vol. 5, No. 1, pp. 28–33.[CrossRef] [PubMed]
- Wang, F.; Wang, Y.; Tian, Y.; et al. Pattern recognition and prognostic analysis of longitudinal blood pressure records in hemodialysis treatment based on a convolutional neural network. Journal of Biomedical Informatics 2019, Vol. 98, pp. 103271.[CrossRef] [PubMed]
- Bi, Z.; Wang, M.; Ni, L.; et al. A practical electronic health record-based dry weight supervision model for hemodialysis patients. IEEE Journal of Translational Engineering in Health and Medicine 2019, Vol. 7, pp. 1–9.[CrossRef] [PubMed]
- Xiong, C.; Su, M.; Jiang, Z.; Jiang, W. Prediction of hemodialysis timing based on LVW feature selection and ensemble learning. Journal of Medical Systems 2019, Vol. 43, No. 1, Article No. 18.[CrossRef] [PubMed]
- Burlacu, A.; Iftene, A.; Jugrin, D.; Popa, I.V.; Lupu, P.M.; Vlad, C.; Covic, A. Using artificial intelligence resources in dialysis and kidney transplant patients: a literature review. BioMed Research International 2020, Vol. 2020, Article ID 9867872.[CrossRef] [PubMed]
- Tenny, S.; Varacallo, M. Evidence Based Medicine. [Updated 2022 Oct 24]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing, Jan 2024. Available online: https://www.ncbi.nlm.nih.gov/books/NBK470182/ (accessed on 8 Aug. 2024).